You picked your AI model. You’re proud of it. Now you need to host it — and you’re staring down two options that look similar on a sales page but will cost you wildly different amounts at 10,000 daily requests.
We’ve deployed AI inference stacks for US-based startups and mid-market enterprises across both platforms.
Here’s what actually happens when you commit to one over the other — and why the wrong choice can cost you $14,000+ a month you didn’t budget for.
The Cost Reality Nobody Puts in the Brochure
Let’s start with numbers, because that’s what this decision comes down to.
AWS Bedrock: Token-Based Pricing
Claude Sonnet 4.5: $3.00/million input tokens, $15.00/million output tokens — a 5x multiplier between input and output that catches nearly every team off guard.
▸ Floor: Amazon Nova Micro at $0.035/million output tokens
▸ Ceiling: Claude Opus at $75.00/million output tokens
▸ Batch inference: 50% discount, but only useful for non-real-time workloads
The Hidden Costs Bedrock Doesn’t Tell You Upfront
A $600/month inference budget balloons past $2,100/month in total AWS spend when you add the full stack:
▸ OpenSearch Serverless (required for Knowledge Bases + RAG) = $350/month floor before you serve a single query
▸ Agent workflows multiply token consumption by 5–10x because of multi-step reasoning loops
▸ Add Guardrails, CloudWatch logging, and API Gateway — and the bill compounds fast
Hugging Face: Compute-Hour Pricing
Predictable, no surprise multipliers — you pay for the GPU, not the tokens.
▸ CPU instance: $0.03/hour
▸ NVIDIA T4 GPU: $0.50/hour
▸ NVIDIA A10G: $1.00/hour
▸ H100: $4.50–$10.00+/hour
▸ 8x H100 node: $80/hour
A small startup running two T4 endpoints 24/7 pays roughly $720/month — predictable.
But Here’s the HF Gotcha
Hugging Face Inference Endpoints have no built-in spending caps or automated budget warnings. A traffic spike or a bug in your inference loop can trigger a bill you don’t see coming until the month closes.
Open Source Freedom vs. Managed Model Catalog
AWS Bedrock gives you a curated catalog: Anthropic’s Claude family, Amazon Titan, Meta Llama, Cohere, Mistral, and others — all served through a single unified API. You don’t manage infrastructure. You call the API, pay per token, and AWS handles the rest. Bedrock Marketplace also added 83 open models from Hugging Face — including Gemma, Llama 3, and Mistral.
Hugging Face is the largest open-source AI model hub on the planet. Over 900,000 public models covering text generation, image recognition, translation, document AI, and more. Deploy any of them via Inference Endpoints on AWS, Azure, or GCP — your choice of cloud, hardware, and framework (PyTorch, TensorFlow, JAX).
The Controversial Take
If your AI application depends on a model that’s available in Bedrock’s catalog and you don’t need fine-tuning, you are over-engineering by choosing Hugging Face. The operational overhead isn’t worth it.
But if you’re running a custom fine-tuned model — a domain-specific LLM trained on your proprietary data — Bedrock cannot host it. Period. You’re back on Hugging Face or SageMaker.
Where AWS Bedrock Actually Wins
Stop trying to build everything from scratch if you don’t have to. Bedrock wins in three specific situations:
Bedrock’s Three Winning Scenarios
Enterprise Compliance
Inherits AWS’s full portfolio — HIPAA, SOC 2, GDPR, FedRAMP. Integrates with CloudTrail and IAM out of the box. Audit-ready for healthcare, fintech, and government clients.
Deep AWS Stack Integration
If you already run Lambda, EC2, RDS, and S3 — Bedrock connects with zero friction. We’ve seen clients cut integration timelines from 6 weeks to 11 days.
Low-Volume Serverless
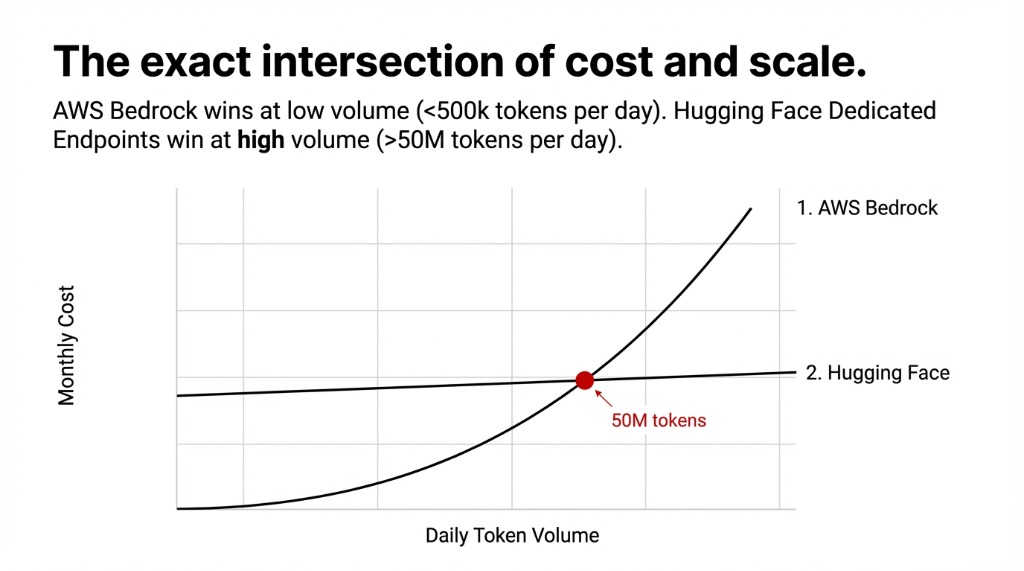
Pay only when you use it. No idle compute costs. For AI features under 500,000 tokens/day, Bedrock on-demand is almost always cheaper.
Where Hugging Face Actually Wins
Here’s the reality most AWS partners won’t tell you: Bedrock is a walled garden with a beautiful lobby.
Fine-Tuning: Where Hugging Face Absolutely Dominates
Bedrock supports fine-tuning for select models (Claude, Titan), but it’s expensive and limited. Hugging Face lets you fine-tune virtually any open model using PEFT, LoRA, and QLoRA, then deploy the fine-tuned weights directly.
For custom vertical AI applications — legal document analysis, medical imaging, manufacturing defect detection — this is the difference between a model at 89% accuracy vs. 61% on your domain data.
Cost at scale tips toward Hugging Face when your workload is consistently high. At 50M+ output tokens per day, a dedicated H100 endpoint at $10/hour ($7,200/month) may actually undercut Bedrock’s per-token pricing. Do the math for your specific volume before assuming serverless is cheaper.
The Integration Traps We See Every Month
Three Traps That Cost You Real Money
Trap 1: Bedrock Agents Aren’t Free
An agent calling 3 tools per query and reasoning over 5 steps processes 7–12x more tokens than a single prompt. A $0.045/query workflow costs $0.38/query in practice. At 100,000 daily queries: $38,000/month surprise.
Trap 2: Idle HF Endpoints
A T4 GPU endpoint sitting idle for 30 days costs $360 with zero requests served. Auto-pause must be configured explicitly — most teams deploying for the first time miss it entirely.
Trap 3: Wrong GPU for Model Size
Running a 70B model on a T4 GPU won’t just be slow — it will OOM-crash. You need at minimum an A100 at $3.60/hour or H100 at $4.50/hour for production throughput.
The Head-to-Head at a Glance
| Factor | AWS Bedrock | Hugging Face Inference Endpoints |
|---|---|---|
| Pricing model | Per token (input + output) | Per compute-hour |
| Model catalog | ~50+ managed + 83 HF models | 900,000+ open models |
| Fine-tuning custom models | Limited (Claude, Titan only) | Any open model (PEFT, LoRA, QLoRA) |
| Infrastructure management | Zero (fully managed) | Minimal (endpoint config) |
| Spending caps | AWS Budgets alerts available | No built-in caps — manual setup |
| Compliance (HIPAA, SOC 2) | Native, audit-ready | Enterprise Hub — requires contract |
| Best for | AWS-native apps, serverless | Custom models, multi-cloud, open-source AI |
| Starting cost | ~$0.035/1M tokens (Nova Micro) | $0.03/hr (CPU) to $80/hr (8x H100) |
Which Platform Should You Pick?
Choose AWS Bedrock If
▸ Your entire stack lives on AWS and you want zero new vendor relationships
▸ Your traffic is unpredictable and serverless per-token billing protects your budget
▸ You need enterprise compliance documentation ready for an audit this quarter
▸ You’re calling foundation models directly without custom fine-tuned weights
Choose Hugging Face If
▸ You’ve fine-tuned a model on proprietary data and need to host it in production
▸ You want model portability across AWS, Azure, and GCP without platform lock-in
▸ Your team is open-source-native and works with Transformers, PEFT, or LangChain daily
▸ Your daily volume makes per-token pricing more expensive than dedicated compute
The Third Option Nobody Mentions
Deploy your open-source Hugging Face models through AWS Bedrock Marketplace. As of early 2025, Bedrock Marketplace hosts 83 Hugging Face models — Llama 3, Mistral, Gemma — on fully managed SageMaker JumpStart infrastructure, accessible through the same Bedrock APIs.
You get open-source model access with AWS-native infrastructure. The hybrid path that eliminates most of the trade-offs above.
We help US-based AI development teams architect the right inference stack for their workload — not the one with the best marketing. If you’re spending more than $3,000/month on AI inference and you’re not sure if you’re on the right platform, check your cloud infrastructure — that’s worth 15 minutes of our time.
The Challenge
Pull up your AI inference bill right now. Separate the actual model costs from the infrastructure overhead — OpenSearch, API Gateway, logging, idle endpoints. What percentage of your total spend is compute you actually needed?
If the infrastructure surcharge exceeds 40% of your model costs, you’re on the wrong platform for your workload.
Frequently Asked Questions
Is Hugging Face free for AI model hosting?
Free to explore via the shared Inference API, but production deployments require Inference Endpoints billed by compute-hour. CPU endpoints start at $0.03/hour. GPU endpoints for real workloads start at $0.50/hour (T4) and scale to $80/hour (8x H100).
Does AWS Bedrock support Hugging Face models?
Yes. Bedrock Marketplace includes 83 open-source Hugging Face models — Llama 3, Mistral, Gemma — deployed via SageMaker JumpStart infrastructure and invocable through the same Bedrock APIs used for Claude and Titan.
What are the hidden costs of AWS Bedrock?
Beyond inference tokens: OpenSearch Serverless ($350/month minimum for Knowledge Bases), Guardrails, CloudWatch logging, and API Gateway. Bedrock Agents multiply token consumption 5–10x per query due to multi-step reasoning. Budget for the full stack.
Can I fine-tune models on AWS Bedrock?
Bedrock supports fine-tuning for select models including Claude and Titan variants. For open-source models like Llama 3 or Mistral using custom datasets, Hugging Face with PEFT/LoRA is the standard approach — Bedrock does not host externally fine-tuned weights.
Which platform is cheaper at high volume?
Under 50M output tokens/day, Bedrock’s serverless per-token model is typically cheaper (no idle costs). At high volumes with consistent traffic, dedicated Hugging Face GPU endpoints often cost less per query. Run the math using your actual daily token count.