Most US companies we talk to are burning money on the wrong LLM infrastructure model. At 50 million tokens per day, using GPT-4o-mini via API costs $2,250/month. Running that exact same workload self-hosted on 4× A10G GPUs? $5,175/month. The "cheaper" route costs 2.3× more. And yet, every week, a CTO somewhere is spinning up an H100 cluster, calling it cost optimization.
This is not a philosophy debate. It is a math problem — and most people are solving it wrong.
Your Cloud Bill Is Lying to You
Here is what the GPU rental ads don’t tell you: self-hosting costs 3–5× more than the raw GPU price alone.
You factor in the H100 at $1.49/hr on Hyperbolic or $6.98/hr on Azure. What you don’t factor in:
The Hidden Costs Nobody Quotes
- •DevOps engineer salary to maintain the inference stack (average $145,000/year in the US)
- •Model update cycles every 6–8 weeks as new versions drop
- •Networking, load balancing, and storage overhead on AWS or GCP
- •Downtime during hardware failures that API providers absorb invisibly
Client Reality Check
When one of our clients in the healthcare AI space insisted on self-hosting Llama 3 70B on Lambda Labs to "save money," their actual monthly spend came to:
$4,300 in GPU costs + $6,100 in engineering hours = $10,400/month
The OpenAI API equivalent for their workload? $1,870/month. They were paying 5.6× more for the privilege of managing their own cloud GPU infrastructure.
The Token Math Nobody Does Before Signing a Cloud Contract
Let’s kill the ambiguity with real numbers. For Llama 3.3 70B, generating 1 million tokens per day costs:
| Platform | Daily Cost (1M tokens) | Type |
|---|---|---|
| DeepInfra (API) | $0.12 | Managed API |
| Azure AI Foundry (API) | $0.71 | Managed API |
| Lambda Labs (self-hosted) | $43.00 | Self-Hosted |
| Azure servers (self-hosted) | $88.00 | Self-Hosted |
At 1M tokens/day, self-hosting on Azure is 733× more expensive than using the API. Read that again.
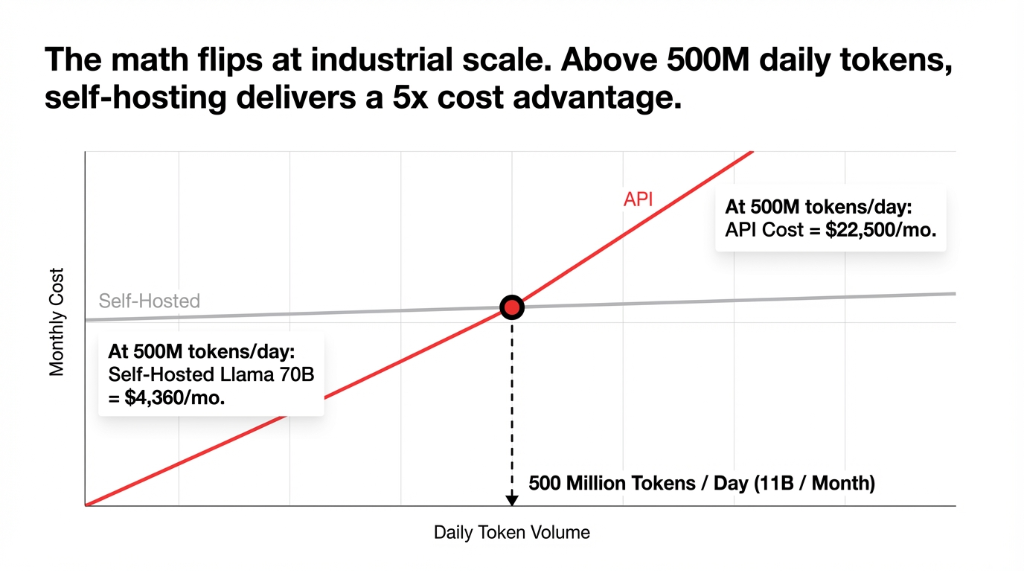
The math only flips when you hit serious, industrial-grade volume. The breakeven threshold is approximately 11 billion tokens per month. Below that, API-based cloud services win on cost. Every single time. At 500M tokens/day, self-hosting a Llama 70B setup drops to $4,360/month versus $22,500/month on API — a 5× win for self-hosting.
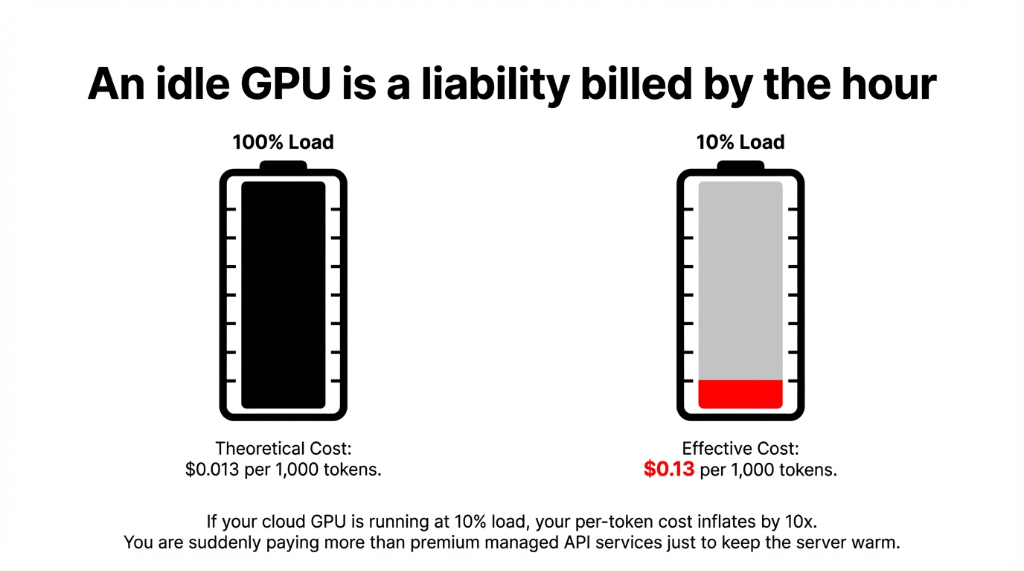
The honest calculation most teams skip: GPU utilization. If your cloud GPU is running at 10% load, your effective cost per 1,000 tokens jumps from $0.013 to $0.13 — more expensive than premium API services. An idle GPU is not an asset. It is a liability billed by the hour.
Performance Is Not Just Speed — It’s Predictability
API-based cloud providers — OpenAI, Anthropic, Google Cloud AI — run massive shared infrastructure. That means latency spikes at peak hours that your latency-sensitive production app will feel. We have seen clients processing medical record summaries via API hit 4.3-second response times at 2 PM EST, compared to 0.8 seconds at 3 AM.
Self-hosted cloud infrastructure gives you predictable, low-latency performance because you control the GPU allocation. For real-time applications — live customer support agents, sub-second document processing, embedded AI in cloud-based healthcare platforms — that consistency is worth paying for.
GPU Requirements by Model Size
Sub-70B Models
L40S or A10G
~$0.0005–$0.001 / 1K tokens
13–70B Models
A100 80GB or H100
~$0.001–$0.003 / 1K tokens
70B+ Models
Multi-GPU H100/H200
~$0.003–$0.01 / 1K tokens
Miss these requirements by one GPU, and your self-hosted "performance advantage" becomes a queuing disaster.
The One Reason Self-Hosting Actually Makes Sense
We are not anti-self-hosting. We are anti-self-hosting for the wrong reasons.
Data Sovereignty Is the Only Non-Negotiable Case
If you are building AI for US healthcare (HIPAA), financial services (SOC 2, SEC regulations), or government contracts, your data cannot touch OpenAI’s or Anthropic’s cloud infrastructure. Period.
In those scenarios, the $6,100 in monthly engineering overhead is not a cost. It is compliance insurance that keeps you out of a $1.9M HIPAA fine.
Outside of regulated industries? The honest answer from our team, after deploying AI workloads for enterprises across the US: API-based cloud services win for 87% of use cases. The flexibility of managed cloud AI services, zero infrastructure maintenance, and instant access to frontier models like GPT-4o, Claude 3.7, and Gemini 2.0 is worth the per-token premium at any volume below 11B tokens/month.
What Nobody Tells You About Scaling
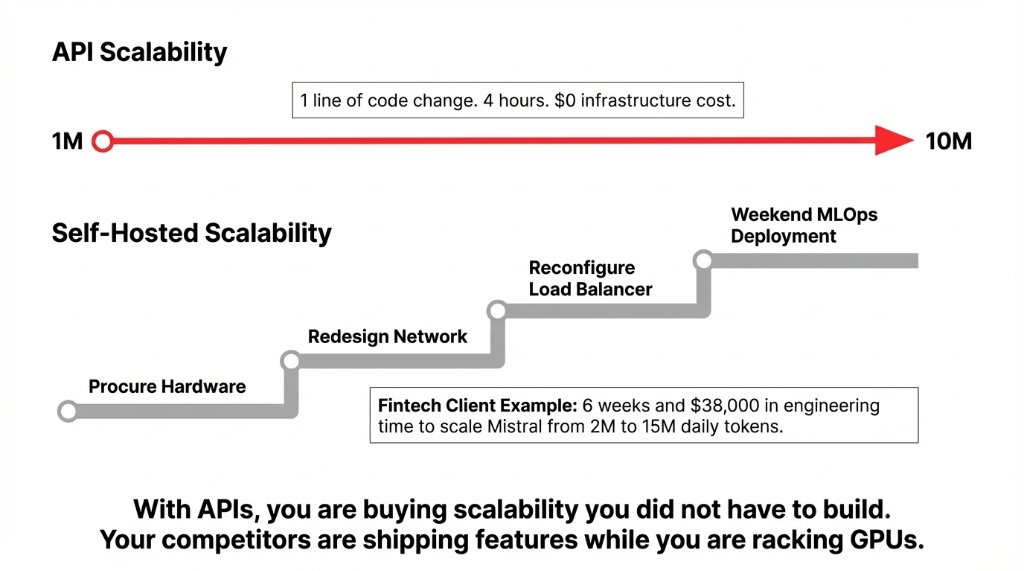
API-based LLMs scale to 10M daily tokens with a single line change in your code. No new GPU procurement, no cloud architecture redesign, no MLOps pipeline updates. You are buying cloud scalability you did not have to build.
Self-hosted cloud infrastructure hits a wall.
Going from 1M to 10M daily tokens does not mean 10× the performance — it means 10× the hardware, plus network redesign, plus load balancer reconfiguration, plus a weekend of your ML engineer’s life.
We saw a fintech client in Austin spend 6 weeks and $38,000 in engineering time scaling their self-hosted Mistral deployment from 2M to 15M daily tokens. An API migration would have taken 4 hours and cost $0. Their competitor shipped three AI features while they were racking GPUs.
The Braincuber Framework: How We Actually Decide
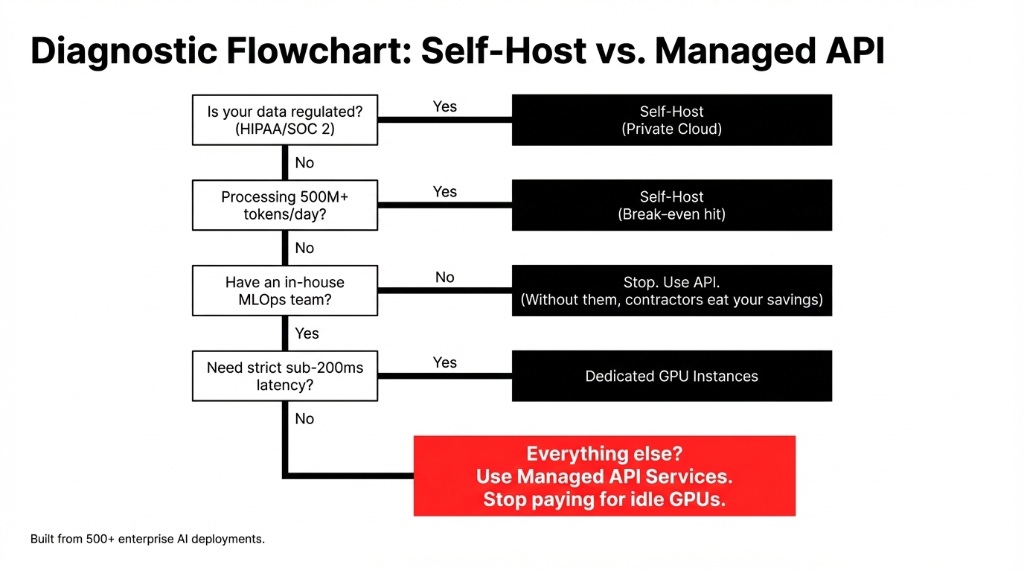
We built this framework after working through 500+ AI deployments. The clients who ignored it are the ones calling us 8 months later to migrate back to APIs after burning $140,000 in cloud infrastructure they did not need.
The Hidden Cost of Model Drift
Models Get Stale. APIs Don’t.
GPT-4o on OpenAI’s API was updated multiple times in 2025 without a single line change on your end. Claude 3.7 Sonnet landed with improved reasoning. These improvements hit your application automatically.
Your self-hosted Llama 3 70B?
Still on the version you deployed in Q3 2025. The re-quantization, testing, and redeployment cycle takes 3–4 weeks and $12,000 in engineering time per update cycle. In a field where model improvements are measured in months, that lag is a real competitive disadvantage.
Stop Guessing Which Infrastructure Model Fits
Pull your last 30 days of token volume. If it’s under 11 billion tokens — and you’re not in a regulated industry — you are overpaying for self-hosted infrastructure right now.
Book our free 15-Minute Cloud AI Audit. We’ll identify your cost leak and the right deployment model in the first call.
Frequently Asked Questions
Is self-hosting an LLM always cheaper than using an API?
No. Self-hosting is only cheaper above approximately 11 billion tokens per month (~500 million tokens/day). Below that threshold, API-based services cost significantly less when you factor in idle GPU time, DevOps overhead, and engineering hours to maintain the inference stack.
What are the main performance differences between self-hosted and API-based LLMs?
Self-hosted LLMs deliver lower and more consistent latency because you control hardware allocation. API-based services can spike during peak demand. However, API providers offer zero-downtime model updates and managed scaling that self-hosted deployments require significant engineering effort to replicate.
When does self-hosting an LLM actually make sense for a US company?
Primarily for regulated industries — healthcare (HIPAA), financial services (SOC 2), and government contracts — where data cannot leave your own infrastructure. The second case is ultra-high-volume workloads exceeding 500M tokens per day, where self-hosting delivers 5× cost savings over API pricing.
What are the hidden costs of self-hosting LLMs that teams overlook?
GPU utilization inefficiency is the biggest leak — a GPU at 10% load inflates your cost per token by 10×. Add DevOps at $145,000+/year, model update cycles at ~$12,000 in engineering time, plus networking and storage. Total real cost runs 3–5× above the raw GPU rental price.
Which cloud GPU providers are most cost-effective for self-hosted LLM inference?
H100 SXM instances range from $1.49/hour on Hyperbolic to $6.98/hour on Azure. Lambda Labs A100 40GB instances deliver 1M tokens/day for ~$43, versus $88 on Azure servers. For smaller models under 7B parameters, AWS Graviton4 CPU instances can serve inference at $0.0008 per 1,000 tokens.