If your entire e-commerce platform lives in us-east-1, you are one AWS outage away from a catastrophic revenue wipeout.
On October 20, 2025, at 2:17 AM EDT, us-east-1 flickered — and companies lost between $500,000 and $10,000,000 in a single incident. That is not a theoretical risk. That is a receipt. us-east-1 alone has had 3 major incidents in the past 5 years.
The difference between those who lost millions and those who barely noticed? Multi-region AWS architecture.
We see this constantly. A brand scales from $500K to $3M ARR, celebrates, and keeps running everything out of one AWS region — usually us-east-1 because it was the default when they first set up. That decision, made in a 10-minute setup flow, quietly compounds into a multi-million dollar infrastructure liability.
The Latency Tax You Are Already Paying
A 1-second delay in page load reduces conversion rates by 7%. If your checkout page serves a customer in London from us-east-1 in Virginia with 180ms latency instead of 20ms from eu-west-1, you just handed that sale to a competitor who thought through their architecture.
And that is on a good day — before any outage happens
If your platform is not multi-region by the time you are crossing $1M ARR, you are gambling with the company. The next us-east-1 incident could land on Black Friday, when every hour of downtime costs double.
The 3-Layer Multi-Region Architecture
AWS spans 39 geographic regions and 123 Availability Zones, with over 400 edge locations powered by nearly 20 million kilometers of fiber optic cabling. That is the backbone you need to use — not just park your app on a single node of it.
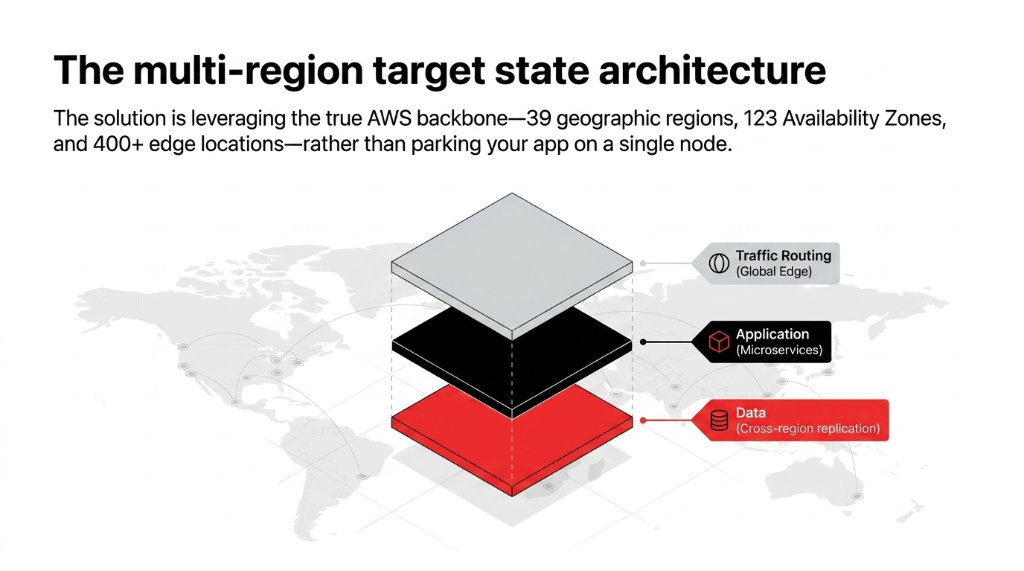
Layer 1: Traffic Routing at the Edge
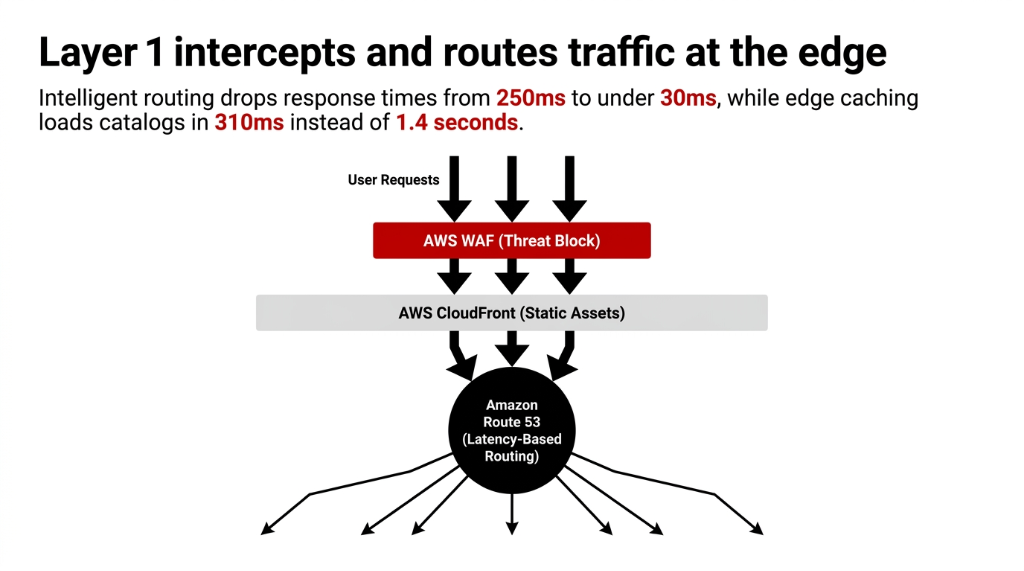
Layer 1: Edge Services
Amazon Route 53
Latency-based routing sends a Tokyo customer to ap-northeast-1, not Virginia. Response times drop from 250ms to under 30ms. Geoproximity routing also supported for fine-grained control.
AWS CloudFront
400+ edge locations cache product images, CSS, and static assets. Your product catalog page loads in 310ms in Munich instead of 1.4 seconds. Target cache hit ratio: 85%+.
AWS WAF
Sits in front of CloudFront to block SQL injection and DDoS before requests ever touch your application layer. (We have seen a $5M brand get scraped dry by bots because WAF was not enabled.)
Layer 2: Application Layer — Isolated Microservices
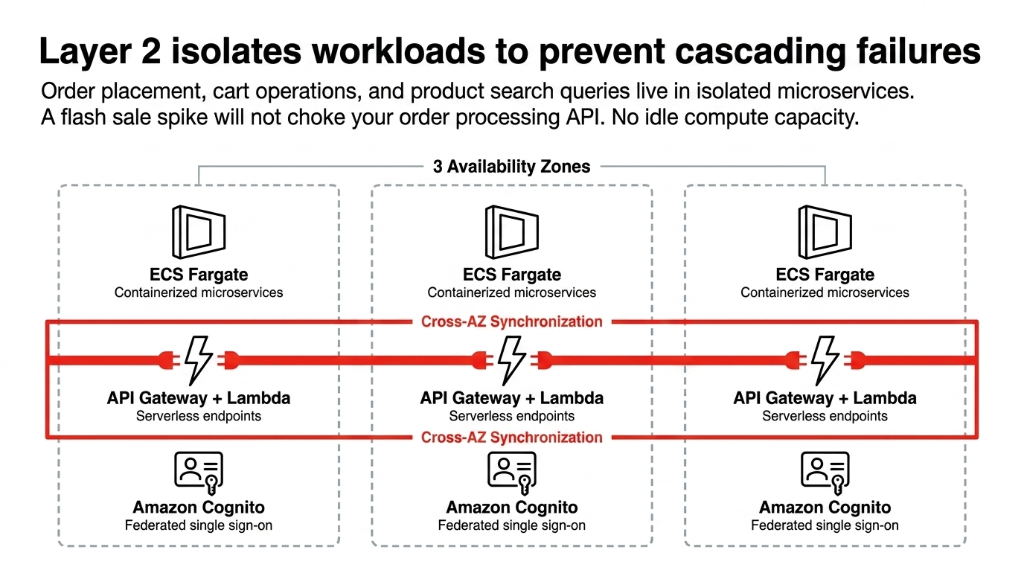
Why Workload Isolation Matters
ECS Fargate runs containerized microservices across 3 Availability Zones per region. No EC2 instances to patch, no idle capacity to pay for. API Gateway + Lambda handles serverless API endpoints — order placement, cart operations, and product search each live in their own function.
A spike in cart traffic during a flash sale does not choke your order processing API
Amazon Cognito handles authentication — one user pool, federated across regions. A shopper who logs in from the US then opens their laptop in Singapore stays authenticated without re-login.
Layer 3: Data Layer (The Part Most Architects Get Wrong)
This is where 73% of multi-region setups fail. People replicate their application layer across regions but leave their database in a single region. So now you have fast routing to a slow database. Congratulations, you spent $40K on an architecture that still has a 400ms query bottleneck.
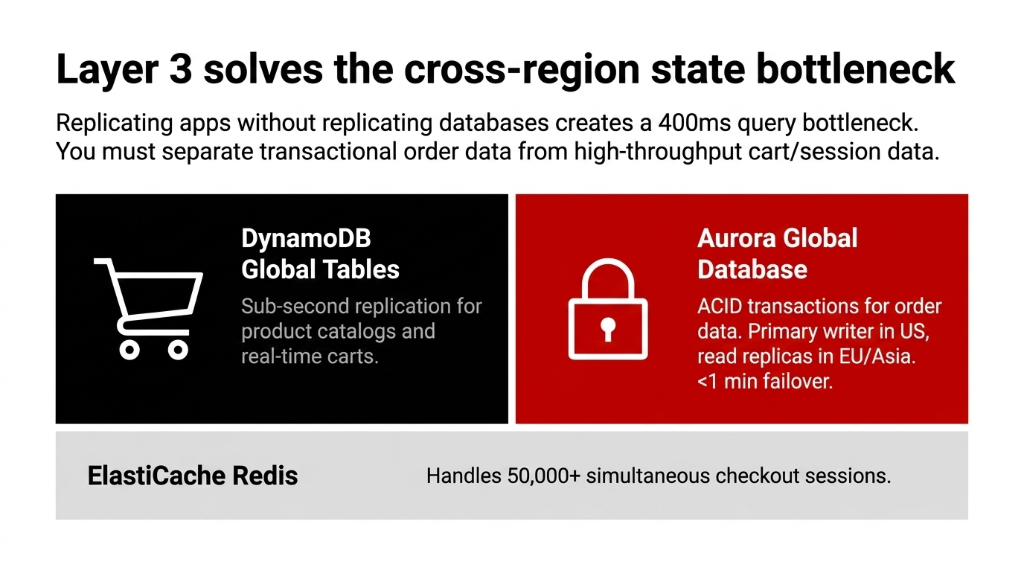
The Data Layer You Actually Need
DynamoDB Global Tables
Replicates product catalog, user carts, and session data across us-east-1, eu-west-1, and ap-northeast-1 with sub-second replication. A user who adds to cart in New York and checks out in Dallas gets a consistent, real-time cart.
Aurora Global Database
Handles transactional order data. Primary writer in us-east-1. Cross-region read replicas in eu-west-1 and ap-southeast-1. Failover to secondary region in under 1 minute. ACID compliance non-negotiable for orders.
ElastiCache Redis
Cross-region sharding handles session caching. Not optional for flash sales — when 50,000 users hit your checkout simultaneously, Redis is the difference between a 120ms response and a 504 timeout.
Active-Active vs. Active-Passive: Pick the Right Model Before You Waste $60K
Everyone on LinkedIn tells you to go active-active. Do not listen blindly.
| Factor | Active-Passive | Active-Active |
|---|---|---|
| How It Works | One live region, warm standby takes over during failover | All regions handle live traffic simultaneously |
| Upfront Cost | $25K–$40K | $50K–$80K+ |
| Monthly Ongoing | ~$5K–$8K/month | ~$10K–$18K/month |
| Uptime SLA | 99.95% | 99.99% |
| Right For | $1M–$10M ARR (start here) | $15M+ ARR |
The Insider Secret About Active-Active
Most AWS consultants will not tell you this: the hard part of active-active is not the infrastructure — it is your application code. If your order management system was not written to handle concurrent writes from two regions, you will create race conditions that corrupt orders.
We have had to rebuild application layers mid-project
A brand was sold an active-active setup their codebase could not support. Go active-passive first. Migrate to active-active when you are crossing $15M+ ARR and your application layer is proven conflict-safe.
The Full Services Stack
| Layer | Service | Purpose |
|---|---|---|
| DNS & Routing | Route 53 (latency-based) | Routes users to nearest region |
| CDN & Edge | CloudFront + WAF | Caches assets, blocks threats |
| Auth | Amazon Cognito | Federated user identity |
| Compute | ECS Fargate / Lambda | Containerized & serverless workloads |
| Product Search | Amazon OpenSearch | Sub-100ms product search at scale |
| Catalog & Cart | DynamoDB Global Tables | Multi-region active replication |
| Orders | Aurora Global Database | ACID transactions + cross-region replicas |
| Session Cache | ElastiCache Redis | Flash sale traffic handling |
| Async Orders | SQS + Step Functions | Fault-tolerant order orchestration |
| CI/CD | CodePipeline | Deploy to all regions simultaneously |
This is not a wishlist. This is what we actually deploy for clients scaling globally.
What It Costs — Real Numbers, Not Estimates
The ROI Calculates Itself
▸ Upfront architecture design, Terraform/CloudFormation, chaos testing: $25,000–$40,000
▸ Ongoing monthly infrastructure (2 regions, ECS Fargate, Aurora Global, DynamoDB Global, CloudFront): $8,000–$14,000/month
▸ Cost of NOT doing this: One us-east-1 outage during peak season = $500,000+ in lost revenue and customer trust erosion
$40K investment vs. $500K+ loss exposure
That is before you factor in the 7% conversion lift from serving US West and EU customers from nearby regions. At Braincuber, in our cloud infrastructure projects across the US and UAE, we have seen brands recover that $40K investment in under 90 days purely from conversion rate improvement on reduced latency — before a single outage ever occurs.
The 6-Week Deployment Reality
Week 1–2: Architecture Design + VPC Setup
Architecture design, Terraform module creation, VPC setup in primary and secondary regions, IAM role structure. This is where the engineering decisions get locked in — region selection, failover strategy, data residency rules for GDPR.
Week 3: Database Replication Layer
ECS Fargate cluster deployment, Aurora Global Database setup, DynamoDB Global Tables configuration. Data replication lag needs to be tested obsessively — target under 1 second replication between regions. This is where 73% of other implementations fail.
Week 4: Edge + Routing Configuration
CloudFront distribution setup with WAF rules. Route 53 health checks and latency routing policies. Redis ElastiCache cross-region sharding. Every CDN cache rule gets tuned to your specific asset types.
Week 5: Load Testing + Chaos Engineering
Simulated traffic at 3x peak load on each region independently. Then simulate a us-east-1 failure and measure actual failover time. Target: Route 53 detects failure within 10 seconds, reroutes traffic within 30 seconds. If it does not hit that target, we fix it before go-live.
Week 6: CI/CD Pipeline + Go-Live
CodePipeline configured to push deployments to all regions simultaneously. Blue-green deployments per region. Go-live. Immediate result: checkout latency for EU customers drops from 1.1 seconds to under 280ms. 30-day optimization follows for CloudFront cache ratios, DynamoDB RCU tuning, and Lambda cold start mitigation.
Frequently Asked Questions
How much does multi-region AWS architecture cost for e-commerce?
Upfront design and deployment runs $25,000–$40,000 for a 2-region active-passive setup. Monthly infrastructure costs land between $8,000–$14,000 depending on traffic volume. Break-even against a single major outage is usually under 90 days for brands at $2M+ ARR.
What is the difference between active-active and active-passive?
Active-passive runs one live region with a warm standby for failover, costing roughly half as much. Active-active routes live traffic to all regions simultaneously for maximum performance but doubles infrastructure costs and requires application-level conflict resolution. Brands under $10M ARR should start with active-passive.
How fast does Route 53 failover during an AWS outage?
Route 53 health checks detect a regional failure within 10–30 seconds. With properly configured TTL and health check intervals, traffic rerouting completes within 30–60 seconds. Actual user-facing downtime in a well-built setup is under 90 seconds.
Do I need both DynamoDB Global Tables and Aurora?
Yes, for different workloads. DynamoDB Global Tables handle high-throughput reads and writes for catalog, cart, and session data. Aurora Global Database handles ACID-compliant transactional order processing. Running orders through DynamoDB without careful design creates data integrity issues at scale.
Will multi-region affect GDPR or data residency compliance?
It can be engineered to comply. Route 53 geolocation routing keeps EU user data within eu-west-1 or eu-central-1. DynamoDB Global Tables and Aurora replicas can be scoped per region. Data sovereignty is a configuration decision, not a reason to avoid multi-region architecture.
Stop Gambling with Black Friday
If your e-commerce platform is growing and you know your current single-region setup is a liability — or if you just survived an AWS outage and want to make sure it never happens again — we will find your biggest infrastructure gap in the first 15-minute call.
Your Platform Is Either Multi-Region or a Ticking Time Bomb
We will tell you exactly where your platform is exposed and what it costs to fix it. No slides. No theoretical diagrams. Just the numbers your single-region setup is hiding from you.
Free audit. Region exposure mapped. Failover gaps identified on the first call.