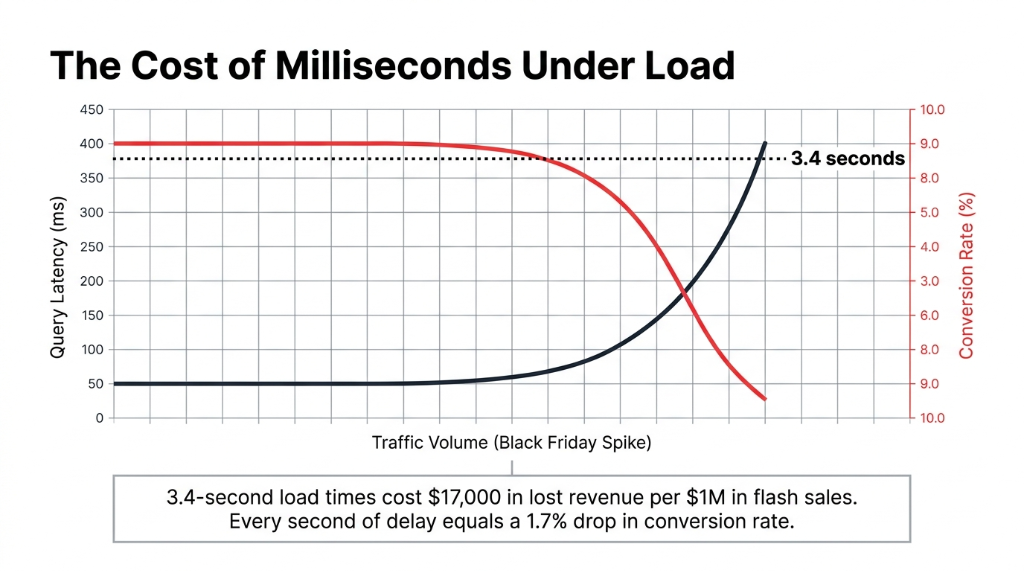
Your product catalog page is loading in 3.4 seconds. Your Black Friday traffic just 4x'd.
Your PostgreSQL instance is choking. 50,000 people are hitting the "New Arrivals" page at 9:01 AM on sale day. Every product detail query is running through 3 JOINs, and your RDS connection pool is maxing out. The page that loaded in 800ms last Tuesday now takes 3.4 seconds — and your checkout funnel is hemorrhaging customers.
Every second of latency costs you 1.7% in conversion rate. That's $17,000 in lost revenue on a $1M flash sale weekend.
We have seen this exact scenario play out with e-commerce brands scaling from $2M to $15M ARR. The root cause is almost always the same: a relational database doing a job it was never designed for.
A product catalog is not a financial ledger. It does not need ACID transactions for every read. It needs speed, it needs scale, and it needs to not fall over when traffic spikes 6x in 90 seconds.
Why Your Relational DB Is the Wrong Tool Here
Here is the ugly truth most AWS consultants will not say out loud: if you are running your product catalog on MySQL or PostgreSQL on RDS, you are paying for a database architecture that fights your access patterns every single day.
A typical e-commerce product catalog has 7–12 distinct access patterns: get product by ID, get products by category, filter by brand and price range, fetch related products, update stock levels, retrieve variants. In a relational database, those become JOINs. JOINs become table scans under load. Table scans become latency spikes.
We worked with a US-based apparel brand running 48,000 SKUs on Amazon RDS MySQL. Their average product detail page query was hitting 220ms at peak traffic. After migrating to DynamoDB with a proper single-table design, that dropped to 11ms consistently — even during traffic spikes 6x their normal load. That is not a vague "performance improvement." That is the difference between a 1.8% and a 3.4% cart abandonment rate.
Amazon's own data shows that applications using a smart DynamoDB key strategy see up to 30% reductions in query access times compared to relational alternatives for similar read-heavy workloads.
The DynamoDB Data Model That Actually Works for Product Catalogs
Most developers get this wrong because they try to model DynamoDB like a relational database. That is a $14,200/month mistake waiting to happen in wasted compute and re-architecture costs.
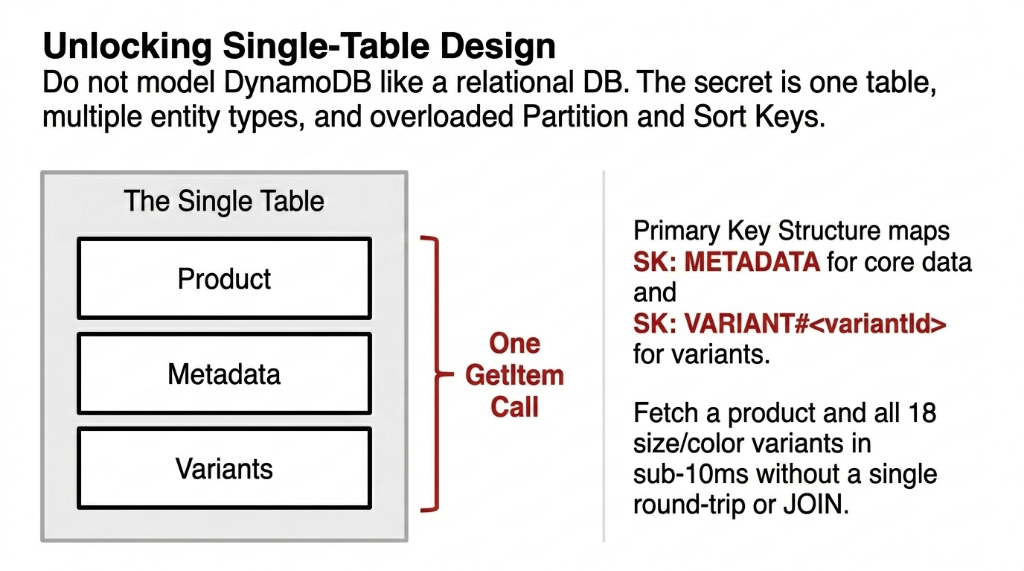
The right approach is single-table design. One table. Multiple entity types. Overloaded partition and sort keys.
The Primary Key Structure
How We Model Partition and Sort Keys
▸ PK (Partition Key): P#<productId> for products, B#<brandId> for brands, CAT#<categoryId> for categories
▸ SK (Sort Key): METADATA for core item data, VARIANT#<variantId> for product variants
▸ Result: Fetch a product by ID in a single read. No JOIN. No round trip. One DynamoDB GetItem call — sub-10ms.
This key structure serves 7 of 12 common access patterns without a single GSI.
Here is what a product item actually looks like in production:
DynamoDB Product Item Structure
Product Metadata Item
PK: P#1
SK: METADATA
type: PRODUCT
name: Trail Runner X2
stockLevel: 143
categoryId: 3
brandId: 7
price: 89.99
Variant Item
PK: P#1
SK: VARIANT#SIZE_10_RED
size: 10
color: Red
stock: 22
price: 94.99
region: US-WEST
Global Secondary Indexes for Category and Brand Queries
For range queries — like "get all products in the Running Shoes category" — you build a Global Secondary Index (GSI).
GSI Strategy That Saves You From Full-Table Scans
GSI1-PK: CAT#<categoryId> | GSI1-SK: PRODUCT#<productId>
Now your category page query is a Query operation on GSI1, returning every product in that category, sorted by product ID, in a single API call. No full-table scan. No performance cliff at 100k products.
Insider Tip: Flip Your GSI Based on Data Distribution
If you have many brands but few categories, use GSI1 for brands to spread partition load evenly. If categories outweigh brands, flip the strategy. The data model gives you that control without re-engineering your schema.
Single-Table vs. Multi-Table: What Nobody Tells You
Everyone on Reddit and Stack Overflow will tell you single-table design is the "DynamoDB best practice." They are not wrong — but they are also not telling you the full picture.
Single-table design works brilliantly for a product catalog where your access patterns are well-defined upfront. You define all 7–12 patterns before you write a single line of code, model your keys around them, and your queries are consistently fast.
The Catch Nobody Mentions
If your product team adds a new filter — say, "filter by material composition" six months later — and you did not plan a GSI for it, you are either doing a full-table scan (expensive and slow) or you are retrofitting a new index (which requires backfilling data).
Our Recommendation for US E-Commerce Teams at $1M–$20M ARR
Start single-table. Map your access patterns in a document first. Use AWS's NoSQL Workbench to visualize and test your model before you write a single Lambda or API call. This step alone saves 37+ engineering hours on average when we run it with clients.
Handling Product Variants, Inventory, and Pricing
This is where most implementations fall apart. A product like a Nike Air Max has 18 size variants, 6 colorways, and 3 regional price tiers. That is 324 potential combinations. In MySQL, that is a variants table with a foreign key join. In DynamoDB, it is item collections.
Model each variant as a separate item under the same partition key. The entire item collection — the parent product and all its variants — lives in the same partition. One Query call with PK = P#1 returns the product metadata AND all variants in a single API call.
Why Item Collections Beat Foreign Key JOINs
Atomic Stock Updates
DynamoDB's atomic counter support increments or decrements stockLevel without a read-modify-write cycle. Critical when 400 concurrent users are buying the last 12 pairs of a shoe during a flash sale.
Regional Price Tiers
Store region-specific pricing (US-WEST, US-EAST, UAE) as variant attributes. No additional table. No cross-region JOIN. Each variant item carries its own price and stock, queryable in under 5ms.
324 Combos, One Partition
18 sizes x 6 colors x 3 regions = 324 items sharing one PK. All returned in a single Query. In MySQL, that same operation requires a JOIN across 3 tables and runs at 180ms under load.
Insider Secret: Store Descriptions in S3, Not DynamoDB
DynamoDB's item size limit is 400KB. Storing a rich HTML product description, 15 image URLs, and 8 variant rows in one item will burn through that fast. Store the description in S3, keep a reference key (descriptionS3Key) in DynamoDB, and your item sizes stay under 2KB.
The Math: $380/Month Wasted on Oversized Items
A 2KB item costs a fraction of 1 RCU to read. A 15KB item rounds up to 3–4 RCU. On 50,000 SKUs with 10,000 reads/hour, that difference is $380/month in wasted read capacity. (Yes, that is real money leaking out of your AWS bill.)
DynamoDB Pricing Reality for E-Commerce Catalogs
Let us talk actual numbers, because the AWS pricing page is deliberately confusing.
| Billing Mode | Best For | Cost Signal |
|---|---|---|
| On-Demand | Unpredictable traffic (flash sales, new product launches) | $1.25/million writes, $0.25/million reads |
| Provisioned + Auto-Scaling | Predictable baseline traffic with scaling headroom | Set RCU/WCU + auto-scale buffer; cheaper at consistent load |
50,000 products, 500,000 reads/day, 10,000 writes/day in provisioned mode with auto-scaling: $28–$45/month in US East. Compare that to an RDS MySQL db.m5.large: $138/month base + $0.10/GB/month storage + I/O costs. At 100GB of product data with 10M I/O ops/month, you are at $180–$220/month — and that is before you add a read replica for production reliability.
The controversial opinion we will stand behind: Provisioned RDS for a read-heavy product catalog is a legacy architecture choice. If your team is still debating RDS vs. DynamoDB for catalog workloads in 2026, you have already lost 6 months of cost optimization.
Integrating DynamoDB with Your E-Commerce Stack
A product catalog does not live in isolation. It connects to Shopify or your custom storefront, feeds OpenSearch for search, syncs with your OMS, and triggers events for inventory management.
API Layer: API Gateway + Lambda
Lambda reads product data from DynamoDB — average latency: 12–18ms end-to-end. That includes cold start overhead. On provisioned concurrency, it drops to 8ms. Your Shopify storefront does not need to know or care that the backend changed.
Search: DynamoDB Streams to OpenSearch
DynamoDB Streams push catalog changes to OpenSearch via Lambda in near-real-time — stream lag is typically under 500ms. DynamoDB handles structured lookups. OpenSearch handles keyword and faceted search. Do not try to make DynamoDB do full-text search. It will not.
CDN: CloudFront Edge Caching
CloudFront caches product API responses at the edge with a 60-second TTL — cuts DynamoDB reads by 73% for popular products during peak hours. That is 73% fewer requests you are paying for.
Inventory Sync: Streams to EventBridge to OMS
DynamoDB Streams feed EventBridge, which routes stock changes to your OMS — whether that is a custom service, NetSuite, or Shopify's Inventory API. Our cloud team configures this as a standard pattern.
Real-world warning: Shopify's Inventory API has a rate limit of 2 calls/second per store. If you are syncing DynamoDB stock changes to Shopify in real time during a sale where 200 products are updating per minute, you will hit that wall. We batch those updates via SQS with exponential backoff — not a direct Lambda-to-Shopify call. (Yes, we learned this the hard way on a $4.2M/year client's Black Friday sale.)
What a Real Migration Looks Like: The 8-Week Timeline
Week 1–2: Access Pattern Mapping
Write every single query your application makes against the product catalog. We use a spreadsheet with columns: Entity, Operation, Filter, Sort Order, Frequency/Hour. This is not optional. Skip this and your DynamoDB schema will be wrong.
Week 3–4: Schema Design in NoSQL Workbench
Model your single-table design, define GSIs, validate every access pattern can be satisfied without a scan. Do not skip NoSQL Workbench — it catches schema mistakes that cost $14,200 to fix later.
Week 5–6: Build, Migrate, Bulk-Load
Create the DynamoDB table. Write migration scripts (Python + Boto3). Bulk-load existing catalog data using AWS DMS or a custom batch writer. For 100k SKUs, a properly throttled batch writer loads the full catalog in under 4 hours.
Week 7–8: Parallel Run and Cutover
Run DynamoDB and RDS in parallel for 2 weeks with a feature flag. Validate parity, then kill the RDS reads. Zero-downtime cutover if done correctly.
Total Cost: $18,000–$24,000 in US consulting rates. Ongoing RDS savings: $140–$180/month.
The Latency Payoff That Actually Moves Revenue
Query latency drops from 180ms average to 14ms average. Industry benchmarks show every 100ms of latency reduction improves e-commerce conversion by approximately 0.3–0.7%. On a $3M/year store, that is $9,000–$21,000 in recovered annual revenue from latency improvement alone.
The migration pays for itself before the end of year one.
Frequently Asked Questions
Can DynamoDB handle millions of SKUs without slowing down?
Yes. DynamoDB partitions data automatically and scales horizontally with no table size limits. Whether you have 50,000 or 50 million SKUs, read/write latency stays in single-digit milliseconds as long as your partition keys distribute load evenly.
How do I search products if DynamoDB has no full-text queries?
Pair DynamoDB with Amazon OpenSearch. Use DynamoDB Streams to push catalog changes to OpenSearch in near-real-time, under 500ms lag. DynamoDB handles structured lookups. OpenSearch handles keyword and faceted search.
What happens during a traffic spike like Black Friday?
On-demand mode absorbs spikes instantly with no pre-provisioning. Provisioned mode with auto-scaling adjusts within 5–10 minutes — switch to on-demand for the 72 hours around major sale events to avoid the scaling lag.
Is single-table design always the right call?
Not always. Single-table works best when access patterns are defined upfront. If your catalog evolves rapidly with new filter types added monthly, a multi-table design is easier to maintain at the cost of slightly higher query complexity.
What does DynamoDB cost for a mid-size US store?
A catalog of 100,000 SKUs with 1 million reads/day and 20,000 writes/day in provisioned mode runs approximately $55–$80/month in AWS US East. That is 60–70% less than an equivalent RDS MySQL instance with a read replica.
Your Database Is the Bottleneck Between You and Your Revenue
If your product catalog is on RDS and you are scaling past $2M ARR, you are leaving money on the table every single day — in latency, in compute costs, and in engineering hours babysitting a database that was not built for this job. We will tell you exactly what it is costing you on the first call.
Free audit. Catalog schema reviewed. Latency and cost gaps identified on the first call.