If you are a US exec pushing AI into your company this year, here is the ugly truth: your data is not ready for AI, and pretending otherwise will quietly burn through six figures before you notice. We keep seeing the same pattern: shiny demos, fancy AI chat tools, zero real outcomes.
The Ugly Math of Bad Data
The Numbers Nobody Wants to Hear
80-90%
AI failure rate because data feeding the models is incomplete, inconsistent, or badly governed.
$12.9M
Gartner's estimate of what poor data quality costs businesses every year, before you add AI.
60%
Gartner predicts AI projects without AI-ready data will be abandoned by 2026. US companies already trending that direction.
The issue is not that you picked the wrong AI engine or the wrong AI software company. The issue is that you tried to bolt artificial intelligence onto data that was never designed to feed AI algorithms.
The Real Problem: You Tried to AI Everything at Once
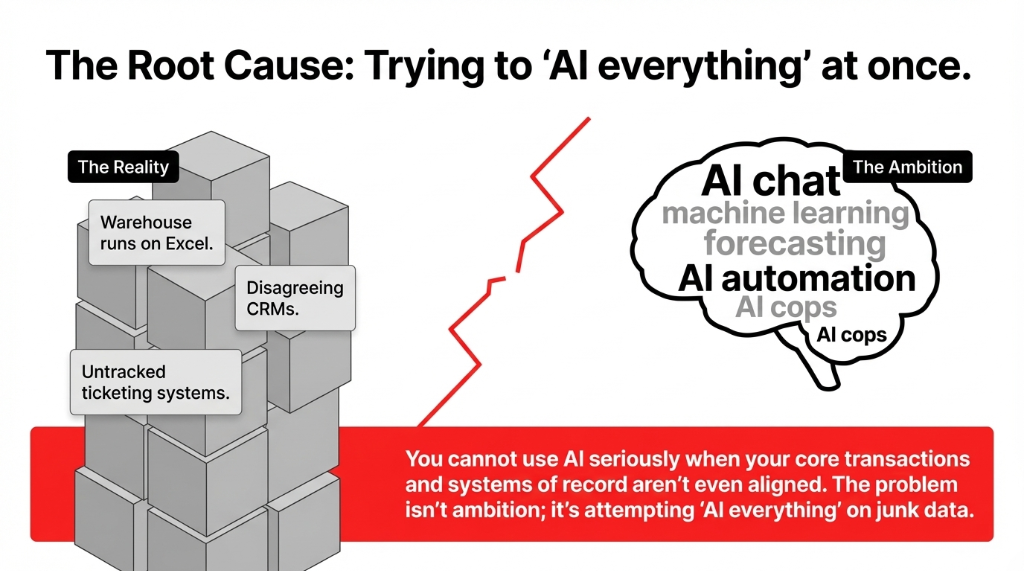
Look at how most US companies approach AI for business: "Let's build an AI chat assistant for customers." "Let's add AI automation to operations." "Let's test machine learning for forecasting." All at once. With the same junk data.
We see boards asking for AI chat, AI copilots, and AI agents while their warehouse is still running on Excel and a shared Gmail inbox. You cannot use AI seriously when your core transactions and systems of record are not even aligned.
The problem is not ambition. The problem is trying to do "AI and everything" instead of doing one tiny, boring thing with AI really well on a clean, narrow slice of data. That is where the idea of a Minimum Viable Dataset comes in.
What We Mean by "Minimum Viable Dataset"
The MVD Definition
The smallest, cleanest, most connected slice of data that is enough to power one narrow, valuable application of AI — and nothing more.
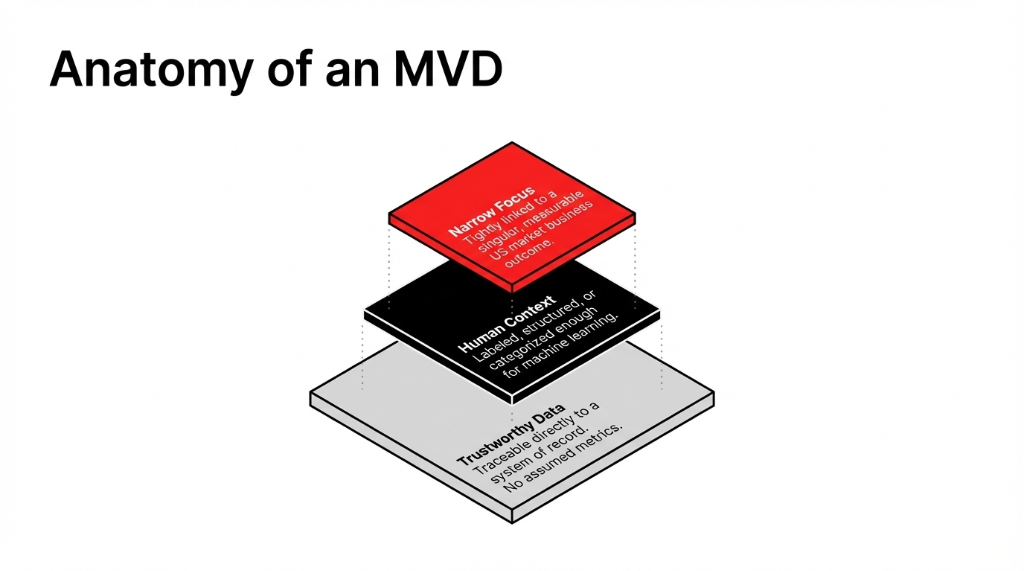
We are not talking about your entire data lake, every log line, and ten years of experiments. For one use case, we pick a tiny subset of data that is trustworthy enough to drive decisions, labeled or structured enough for AI learning, and linked tightly to one business outcome in the US market you actually care about. Everything else goes into the "later" bucket.
Instead of asking, "Are we AI-ready as a company?" we ask, "What is the minimum viable dataset we need to reduce one specific cost line by $23,700 in the next quarter?"
A US Story: How One AI Pilot Quietly Wasted $187,000
A mid-market retail brand in the US came to us after spending about $187,000 on an AI program.
What They Had (On Paper)
▸ A vendor promising AI recommendation engine magic
▸ An internal task force discussing AI in every steering meeting
▸ A slide deck filled with "AI automation" and "AI in industries"
What They Actually Had (In Reality)
▸ Three CRMs, all disagreeing on the same customer's email
▸ A ticketing system where 41% of tickets had no proper category
▸ A product catalog where "navy" and "blue" were different items
They tried to build a recommendation and personalization engine on top of that. Predictably, it failed. Not because AI is weak. Because the data was garbage.
When we dug in, we threw away 90% of their data for this project and focused the first phase on one thing: deflecting support tickets about returns.
Their Minimum Viable Dataset
Table 1: Last 12 months of tickets with a clear "reason for contact" field.
Table 2: Order IDs linked to those tickets with basic attributes (SKU, price, date).
Table 3: A simple label: "Could this have been answered by a self-service article?" Yes/No.
Three tables. Around 280,000 rows. That was it.
Step 1: Stop Saying "AI" and Pick a Boring Business Outcome
If your mind jumps to AI chat or some AI assistant, pause. Instead, ask: What line item on our US P&L hurts the most right now? Where can AI realistically move the needle in 90 days?
Examples of Boring, Measurable Outcomes
Support: Reduce average handle time on support calls by 23%.
Finance: Cut invoice processing time from 27 minutes to 4 minutes.
Marketing: Increase email upsell acceptance by 3.7%.
Do not obsess about "AI strategy" at the corporate level. We focus on one concrete application that a COO can measure in dollars, not vibes.
Step 2: Map the Data You Actually Have
Next, we list every relevant source of data inputs connected to that outcome: CRM records, ERP entries, Shopify orders, email logs, call transcripts, internal documents, any BI dashboard or spreadsheet people already trust.
The Ruthless Rules
Traceability: If we cannot trace a dataset back to a system of record, we do not use it in the first MVD. No matter how tempting.
Structured data: Perfect for traditional AI algorithms and machine learning.
Unstructured data: Tickets, PDFs, call notes — can still feed AI models if handled carefully. Often the messy data lake is far less reliable than boring, stable tables in the ERP.
Step 3: Define the Minimum Viable Dataset
Now we design the MVD with a set of ruthless questions:
The Three MVD Questions
1. What are the must-have features the model needs?
2. What is the minimum time range that still represents the current US reality?
3. What labels already exist, and what can humans add quickly?
Example: Support Deflection Pilot
Fields: Issue category, product type, channel, resolution code.
Time window: Last 9-12 months, not five years of outdated behavior.
Labels: "Self-service answerable = yes/no," added by agents reviewing past tickets.
We do not pull every metric "just in case." We explicitly say no to "let's add more because our AI engine might discover hidden patterns." That mindset is how you end up with a bloated, brittle dataset that no one can debug.
The only question that matters: Is this data field necessary to ship this one use case?
Step 4: Fix Data Quality That Actually Matters
Instead of trying to clean every dataset in the company, we laser-focus on the MVD: remove duplicates that affect this application, normalize critical fields (SKUs, IDs, state codes), impute or drop records with missing labels where they affect training.
The research community now offers checklists for nulls, outliers, provenance, and labeling to help teams judge whether a dataset is actually ready for AI. We take that thinking and apply it in a brutally practical way: if this data point can break our model's decision in production, we fix it now. If not, we ignore it.
Step 5: Ship Something Small, Measurable, and Real
Once the MVD is clean enough, we finally build AI. Not a giant platform. A focused workflow for one team.
What "Ship Small" Actually Looks Like
A bot embedded in the help center that only answers questions about returns.
A model that tags invoices and routes them automatically.
A constrained recommendation system that tests one additional product recommendation.
Treat it like any US product experiment: clear success metrics, tight feedback loop, short 60-90 day window. Then iterate the dataset itself — not just the model.
How This Plays Inside a US Company
Inside a typical US mid-market firm, the reality looks like this: Sales uses a CRM with inconsistent stages. Ops runs on a mix of NetSuite, QuickBooks, and spreadsheets. Customer care lives in a separate ticketing tool. Marketing tracks performance in yet another system.
Then someone green-lights AI plans. "Let's use AI in industries best practices." "We should have an internal AI assistant." Underneath that, the data is siloed, partially labeled, and out of date.
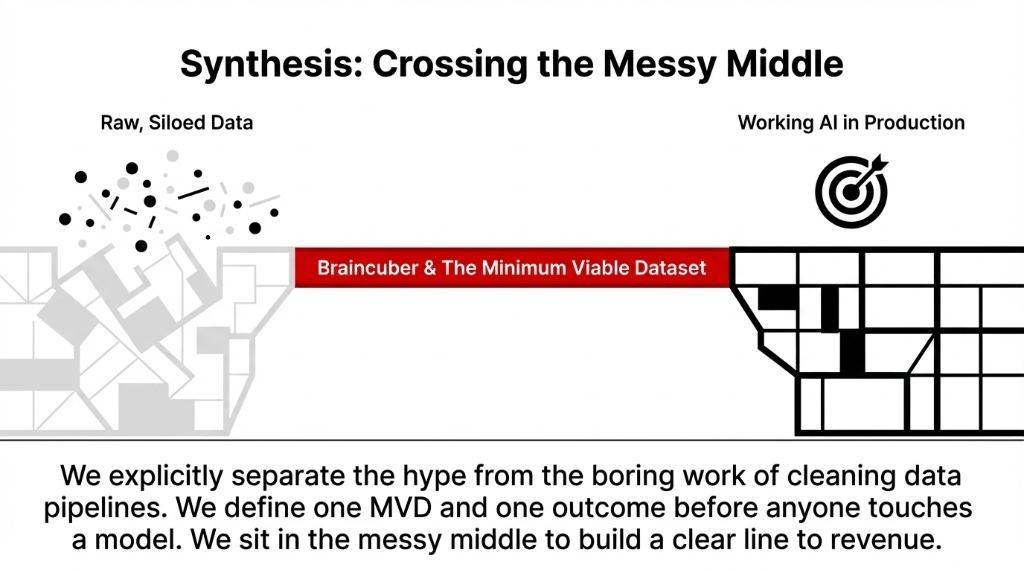
When we step in as Braincuber, we cut through the noise. We explicitly separate the AI hype from the boring work of cleaning data pipelines. We treat AI initiatives as serious operations projects, not science experiments. We define one Minimum Viable Dataset and one outcome before anyone touches a model.
Only after that do we talk about fancier topics like AI personalization, recommendation engines, or AI for learning content experiences.
What You Should Do in the Next 30 Days
The 30-Day Playbook
1. Pick one use case. Something boring but measurable: ticket deflection, invoice coding, churn prediction. Tie it directly to revenue or cost.
2. List your systems. Which databases, CRMs, ERPs, and AI tools touch that process. Ignore everything else.
3. Define your MVD. Name the exact tables and fields you need. Decide the date range. Decide how you will label outcomes.
4. Audit data readiness. Using simple checklists (nulls, outliers, provenance, legal), grade your dataset honestly.
5. Ship a tiny pilot. Use a focused AI partner or build a light internal workflow. Measure it like any other product launch.
At Braincuber, we sit in the messy middle: we work with your US team to pick that first use case, design the Minimum Viable Dataset, and then build the actual AI solutions that ride on top of it. We do not promise magic. We promise a clear line from data, to Minimum Viable Dataset, to working AI in production.
FAQs
How do I know if my data is ready for AI?
If your reports never agree, tickets lack clear categories, or teams say "we don't trust the numbers," your data is not AI-ready. Start by grading one narrow dataset against basics: completeness, consistency, ownership, and recency. If it fails those, fix that slice before thinking about models.
Do I need a data lake before using AI?
No. Many failed projects started by dumping everything into a lake first. For a Minimum Viable Dataset, you usually need a few clean tables from existing systems, clear labels, and governance around that tiny slice. You can expand after the first success.
What is the difference between an MVD and a full data platform?
A full platform tries to serve every future use case; it is long, expensive, and often never finished. A Minimum Viable Dataset serves one AI application end-to-end, fast. Once that works, you clone and extend the pattern to other use cases.
Where should I start if I am completely new to AI?
Forget the buzzwords and pick one measurable business problem first. Map the data touching that process, define a Minimum Viable Dataset, and test a contained AI pilot. You will learn more from one real deployment than from ten webinars.
How can Braincuber help with our AI and data strategy?
We work as a hands-on partner: auditing your current systems, defining your Minimum Viable Dataset, and building targeted AI workflows on top of that slice of data. Because we combine AI, cloud, and ERP experience, we focus on real operational outcomes for US businesses, not just demos.
Stop Bleeding Cash on AI That Runs on Bad Data
If your last AI vendor never asked to see your data before they quoted, you got sold slideware. Book our free 15-minute operations audit. We will find your biggest AI data leak in the first call. No decks. Just your data and a blunt conversation about what is fixable in 30 days.