Our client — a $23M/Year US operations software company — was processing 14,000 documents across procurement, HR, and finance. Their invoice lead time was 12 days. They had an 11 person team manually validating extracted fields before they hit downstream systems.
Everyone told them to upgrade their OCR. That is terrible advice. Their QA team was spending 37 hours per week on post-extraction correction — $89,700/year in labor doing what an intelligent document processing architecture handles in 1.2 seconds.
The Master Architecture Layer by Layer
At Braincuber, we have run 500+ production deployments on aws ai infrastructure. Here is exactly what the pipeline looks like.
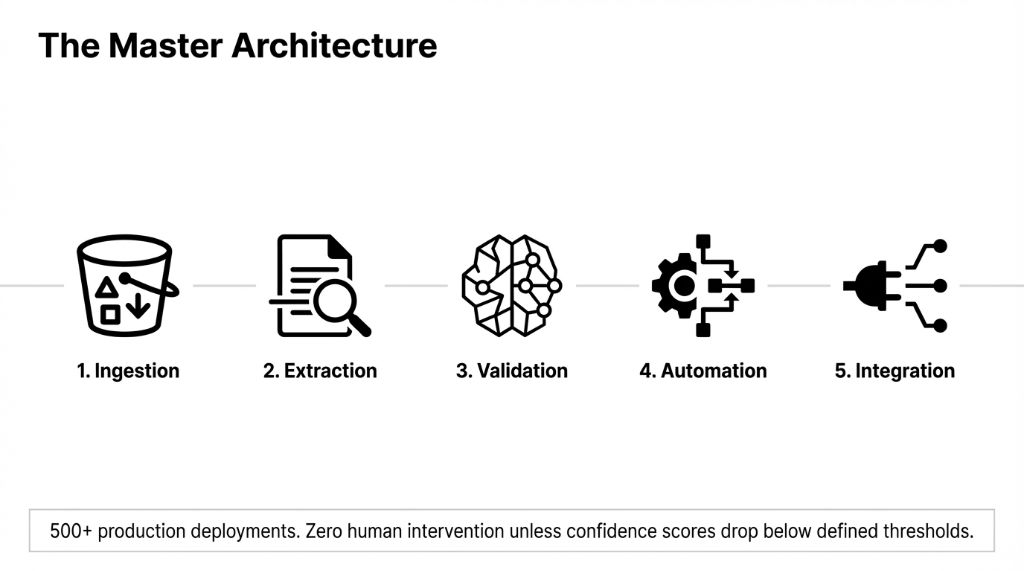
- Ingestion (S3 + Lambda): Every new document is intercepted automatically and routed into the correct processing branch. Team stops sorting paperwork manually.
- Extraction (Amazon Textract): We bypassed standard OCR. Textract understands tables, checkboxes, and signature pdf layouts automatically, hitting 99.9% text accuracy without templates.
- Validation (AWS Bedrock): We pass output to Amazon Nova Pro to cross-check math, validate vendor names against their customer relations management software, and flag anomalies based on specific semantic confidence.
- Automation (Step Functions): Escalate exceptions and trigger multi-level approval chains natively via an automated workflow process.
- Integration (API Push): Clean data hits their accounting software business pipeline, HR tools, and systems automatically. No manual re-keying.
90-Day ROI Reality
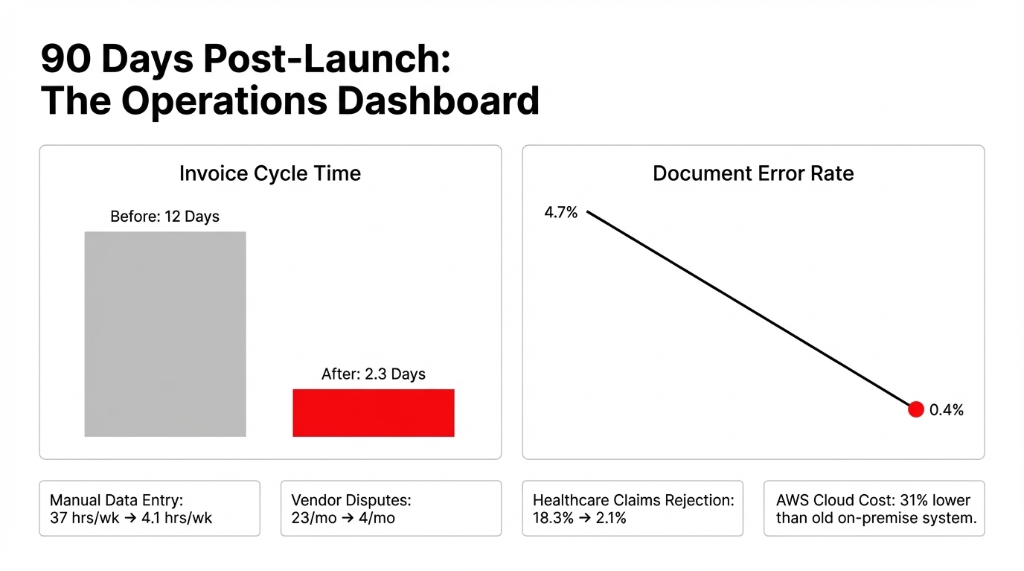
Invoice cycle time: 12 days to 2.3 days.
Data entry hours: 37 hrs/week to 4.1 hrs/week.
Total first-year ROI: 287%.
For their healthcare arm dealing with electronic medical record systems, their claims rejection rate dropped from 18.3% to 2.1%. That recovered $193,400 in previously rejected reimbursements in two quarters alone.
What Implementation Actually Looks Like
Stop buying off-the-shelf software tools that don't fit your core problems. Here is how genuine business process automation goes live.
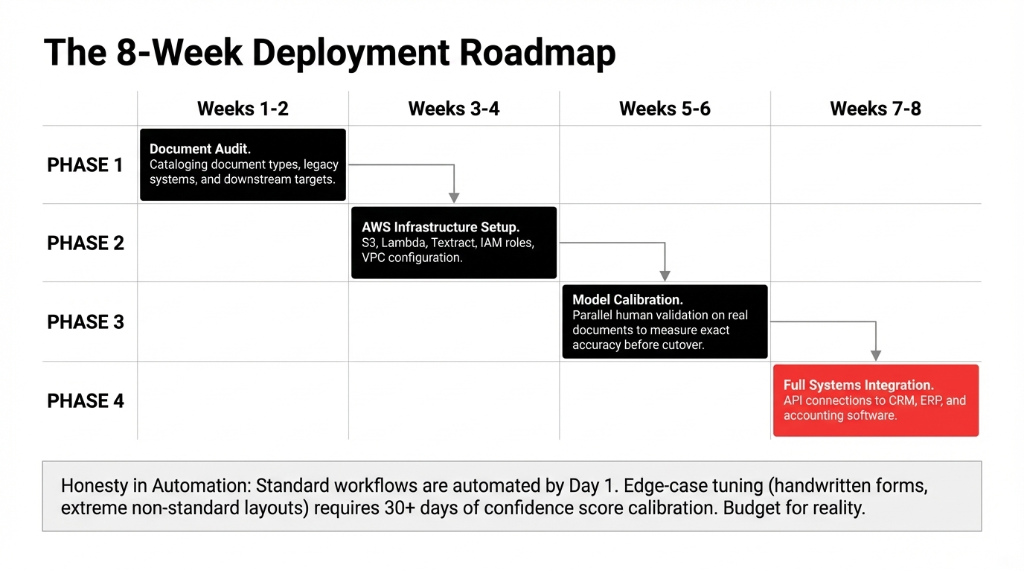
Week 1-2 starts with a core Document Audit. By Week 4, your AWS Infrastructure sits ready. The real effort—Weeks 5 through 8—is running parallel Model Calibration using testing to measure actual confidence scores on edge case inputs before full System Integration.
Replace $12 Manual Entry with $0.13 AWS Inference
You're paying $8–12 per document for human data entry. This pipeline runs it at $0.13. Book your 15-Minute Operations Audit to see how this fits your exact data stack.
FAQs
How accurate is this AWS AI pipeline on real-world scanned documents?
Amazon Textract hits 99.9% text accuracy and 98.2% table recognition on standard business documents. For low-quality scans or handwritten forms, accuracy drops to 80–87%. That's why we layer AWS Bedrock semantic validation on top — so every extracted field gets a confidence score and anomalies get flagged before touching any downstream system.
Can this connect to our existing customer relations management software or ERP?
Yes. The output layer pushes structured JSON via REST API to any system with an API — Salesforce, HubSpot, QuickBooks, SAP, Odoo, NetSuite, or any custom software development build your team is running. We've integrated with 30+ platforms.
How does this handle electronic health records software and HIPAA compliance?
The pipeline supports fully HIPAA-compliant architectures on AWS — encryption at rest and in transit, VPC isolation, CloudTrail audit logging, and least-privilege IAM policies. For electronic medical record systems workflows, we validate extracted fields against your EMR schema before any data touches a downstream system.
What does running this pipeline actually cost per month on AWS cloud services?
For 14,000 documents/month, our client pays $1,840/month in AWS service costs (Textract + Bedrock + Lambda + S3 + Step Functions). That's $0.13 per document — versus $8–12 per document in manual processing costs.
Do we need a big in-house IT team to maintain this after launch?
No. The entire pipeline is serverless — no infrastructure to patch, no servers to scale manually. AWS handles concurrency and scaling automatically. A single developer or cloud IT services partner manages ongoing model tuning and maintenance.