If your e-commerce finance team is still keying invoice data into Excel, QuickBooks, Xero, or NetSuite by hand, you are paying people to do work Amazon Textract can read in seconds.
We see the same mess over and over. A marketplace invoice lands in email, somebody downloads it, renames it badly, uploads it to a shared folder, copies five values into the ERP, misses one tax line, and the payment approval gets delayed by two days. That is not "operations." That is expensive clerical drag wrapped in false comfort.
Impact: $17,500/month in wasted finance headcount and duplicate payment errors.
Where E-Commerce Teams Break
E-commerce invoice processing gets ugly because invoices do not arrive in one neat format. They come from suppliers, 3PLs, ad platforms, packaging vendors, returns partners, and freight companies as PDFs, scans, mobile photos, and mixed-quality exports. Amazon Textract is designed to process scanned documents and extract text, handwriting, tables, layout elements, and data from them.
This is exactly where plain OCR disappoints people. Basic OCR can read characters, but Amazon Textract goes further by identifying and extracting structured data from documents. For invoices and receipts it can map extracted content into a standard expense-oriented schema through AnalyzeExpense.
For e-commerce operators, that difference matters more than the brochure language suggests. You do not just want "text from a page"; you want invoice number, due date, subtotal, tax, total, vendor address, and every line item tied back to a finance workflow. AnalyzeExpense is specifically designed to extract those from invoices and receipts.
The ugly truth is that invoice errors are rarely dramatic. They are small. One duplicate entry, one missed freight surcharge, one wrong tax field, one SKU description that never gets checked against a purchase order. Then month-end arrives, and finance has to reconcile chaos created by manual handling that should never have existed in the first place.
Why Textract Fits Invoices
Amazon Textract offers specialized support for invoices and receipts through AnalyzeExpense. AWS documentation says it can automatically extract summary fields and line-item details while understanding the context of the document rather than just detecting raw text blocks.
That matters for e-commerce because invoice processing is not one field deep. A single supplier invoice may contain dozens or hundreds of line items, shipping charges, discounts, tax lines, currency references, and payment terms. AnalyzeExpense is built to return both summary fields and grouped line-item data from those documents.

Another practical win is that you do not have to start with a template library for every vendor. AWS positions Textract as a pretrained service for document processing, and its invoice and receipt analysis is presented as working without manual templates for those standard document types.
That saves time at the beginning, but more importantly it reduces the usual vendor-onboarding friction. Your team does not need to wait until engineering designs a parser for Supplier A, then another parser for Supplier B, then another parser when the freight carrier changes its PDF format next quarter.
What the Pipeline Looks Like
The most sensible pattern is brutally simple. In AWS's own invoice-processing reference architecture, invoice documents are stored in Amazon S3, an event triggers processing, AWS Lambda calls Amazon Textract, and the extracted results are then parsed and written back for downstream use.
In a real e-commerce stack, we would usually shape that flow like this:
Supplier invoice lands in S3.
An S3 event or EventBridge rule starts the workflow.
Lambda calls Textract AnalyzeExpense for extraction.
Parsed JSON is normalized into finance-friendly fields and line items.
The result is pushed into your ERP, AP queue, or exception review layer.
AWS's sample pipeline for invoice and receipt processing explicitly uses S3, EventBridge, Lambda, the AnalyzeExpense API, and post-processing utilities to convert the response into more usable formats such as CSV. That is a strong fit for e-commerce because invoices are already arriving as files, and file-driven event architecture is far cleaner than forcing staff to upload documents into a custom screen one by one.
Extraction Is Only the First Half
The second half is validation. You should compare Textract output against purchase orders, vendor masters, tax rules, receiving data, and expected tolerances before posting anything into QuickBooks, Xero, NetSuite, SAP, or your custom ERP.
AWS shows the extraction layer
Your finance controls must handle the approval layer.
What AnalyzeExpense Actually Returns
AnalyzeExpense is not just a text dump. According to AWS, the API extracts standardized summary fields such as vendor name, invoice date, total, tax, and other normalized invoice or receipt attributes, and it also returns grouped line-item details.
That standard taxonomy is useful when your documents are inconsistent. One vendor may write "Invoice No." while another writes "Bill #" and a marketplace receipt may expose something different again. Textract's expense analysis is designed to map document content into normalized field types where possible.
For e-commerce teams, that means you can build one downstream schema instead of dozens of vendor-specific ones. Your payable workflow can look for a common invoice ID field, total amount field, or line-item structure even when the source layouts differ.
The Bad Architectural Decision
Teams use generic document analysis because it sounds flexible, then spend months rebuilding invoice logic themselves. For invoice-heavy operations, AWS already provides AnalyzeExpense specifically for invoices and receipts, so starting there is usually the smarter move.
Cost, Speed, and Scale
Amazon Textract is billed per page, and AWS positions it as a document-processing service that can extract data in minutes instead of hours or days. For a finance team handling invoice batches every day, that shift is less about hype and more about capacity: fewer hours wasted on reading PDFs and more time spent on exceptions, approvals, and vendor disputes.
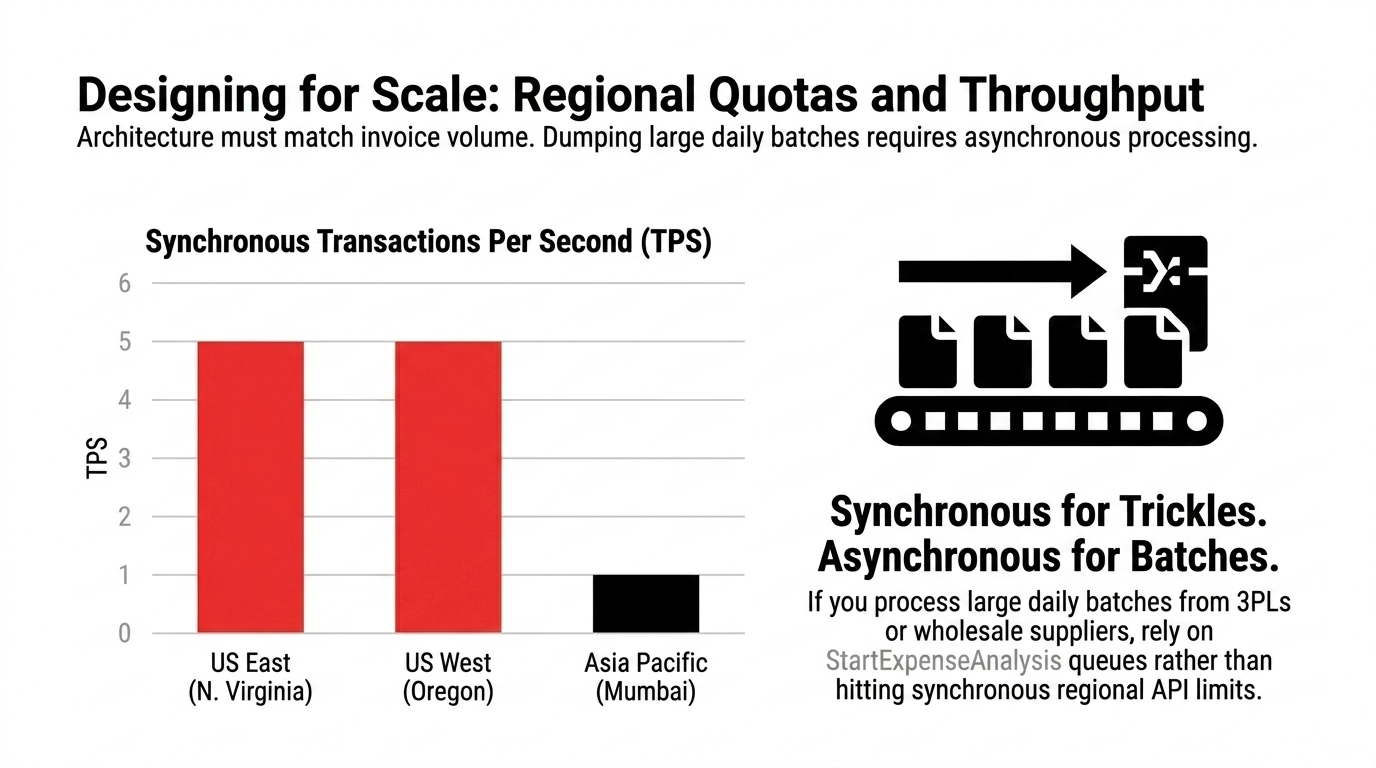
Scale is where design discipline starts to matter. AWS's service quotas show that synchronous AnalyzeExpense transactions per second vary by Region, with 5 TPS in US East (N. Virginia) and US West (Oregon), 1 TPS in regions including Asia Pacific (Mumbai). Asynchronous StartExpenseAnalysis quotas also vary by Region.
That means your architecture should match your volume. If you process a steady trickle of invoices, synchronous calls can be enough. If you dump large daily batches from marketplaces, 3PLs, or wholesale suppliers, asynchronous processing and queue-based orchestration will hold up better under load.
AWS also documents that Textract has set quotas and default quotas, with some limits changeable through Service Quotas and others fixed. So before go-live, do not just test extraction accuracy; test throughput, retries, and backlog behavior during the busiest day of your month.
Where Teams Get Burned
The first mistake is trusting extraction without confidence rules. Textract is strong, but invoices in the wild are messy: skewed scans, cut-off photos, faint print, multilingual vendor data, handwritten notes, and line-item tables that look clean to a human but chaotic to a parser. AWS describes Textract as extracting text and data from scanned documents, but practical production use still requires exception handling around low-quality inputs and validation logic.
The second mistake is pretending one document API solves the whole payable process. It does not. Textract extracts; your workflow still has to manage duplicate detection, tax checks, PO matching, approval routing, and posting logic. AWS's own pipeline examples focus on extraction architecture, which tells you something important: the service is a strong document understanding layer, not your full AP system.
The third mistake is ignoring regional quotas until launch week. AWS publishes different transaction-per-second limits for AnalyzeExpense by Region, so a team building in Mumbai should not assume the same synchronous throughput available in N. Virginia or Oregon.
How We Would Implement It
We would start with one invoice lane, not every document in finance on day one. Feed supplier invoices into S3, use Lambda to call AnalyzeExpense, normalize the output, then route each document into either auto-approval or exception review based on business rules such as total variance, missing PO, or unknown vendor.
Next, we would define a clean target schema. That schema should include vendor ID, invoice number, invoice date, currency, subtotal, tax, total, payment terms, and line items, because Textract's expense response is designed to provide both summary fields and item-level data.
After that, we would instrument the ugly parts. Track exception rate, duplicate rate, extraction confidence thresholds, average review time, and vendor-specific failure patterns. If one freight vendor sends terrible scans every Friday, you want that exposed in a dashboard instead of buried in somebody's inbox.
Then we would connect it to the systems that actually matter. That could be QuickBooks for accounting, NetSuite for ERP, a warehouse billing process, or a custom payout reconciliation layer. Textract should sit at the front of that workflow like a disciplined intake clerk that never gets tired, not as a disconnected AI demo that creates one more dashboard nobody uses.
What Good Looks Like
A good Textract-based invoice workflow does three things well. It ingests documents automatically, extracts normalized invoice data through AnalyzeExpense, and sends only questionable records to humans for review instead of forcing humans to touch every invoice.
That operating model is a better fit for e-commerce than manual keying because invoice volume rises with vendor count, channel count, and fulfillment complexity. Your business should not need to add headcount every time procurement, shipping, or marketplace fees become harder to reconcile.
The story here is simple. You start with invoice chaos, stop treating PDF reading as skilled labor, use Textract to extract what the document actually says, and build rules around the output so finance people review exceptions instead of retyping vendor paperwork. AWS already gives you the document intelligence layer; the win comes from wiring it into a controlled e-commerce workflow.
Your Invoice Process Is Either Saving You Money or Burning It. There Is No Neutral.
If you are running an e-commerce operation above $50K/month and your invoice processing is still a finance lead keying data into spreadsheets, you are likely losing $11,300–$22,000/month in wasted headcount and payment errors. Book our free 15-Minute AWS Operations Audit — we will show you exactly where your current stack is leaking revenue on AWS. No pitch deck. Just data.
Frequently Asked Questions
Is Amazon Textract only OCR?
No. AWS says Textract goes beyond basic OCR by extracting structured data, tables, handwriting, layout elements, and document-specific information from scanned files. For invoices and receipts, AnalyzeExpense adds purpose-built field extraction and line-item grouping.
Which Textract API is best for invoices?
For invoices and receipts, AWS directs users to AnalyzeExpense. It is designed to extract normalized summary fields and line items from those document types, which usually makes it a better starting point than generic document analysis for payable workflows.
Can Amazon Textract handle scale for e-commerce invoice processing?
Yes, but architecture matters. AWS publishes regional quotas for synchronous and asynchronous expense analysis, so scaling depends on your Region, call pattern, and whether you design for batch processing, retries, and queue-based orchestration.
Do we still need human review after Textract extraction?
Usually, yes. Textract can automate extraction, but finance controls still need to catch duplicates, PO mismatches, tax issues, and low-confidence records before posting data into accounting or ERP systems.
What is the simplest starting architecture for Textract invoice processing?
AWS's sample approach is straightforward: store invoices in S3, trigger processing with events, call Textract from Lambda, parse the response, and write the output for downstream systems or review queues. That is the cleanest starting point for most teams.
Talk to a practice lead
Getting hit by surprise AWS bills?
Free AWS cost audit. Send your last 3 invoices and your Cost Explorer view; we return a written report with the top 3 cost leaks and projected savings in 48 hours.
Founder and CEO of Braincuber. Has scoped and shipped 500+ Odoo, AI, and cloud projects for US mid-market and global brands. Takes every founder call personally — no SDR layer between buyers and the people building the system.