Stop pretending that scripting Flask around pickled Python models is scalable. If you build a machine learning model and manually deploy it to raw EC2, you are a liability when that model breaks at 2 AM.
Why Your Deployment Strategy is Breaking
We have rescued aws for machine learning setups at companies spending $85,000/month just trying to figure out model deployment plumbing. They avoid aws sagemaker because they think it's too heavy. Then their EC2 instances crash.
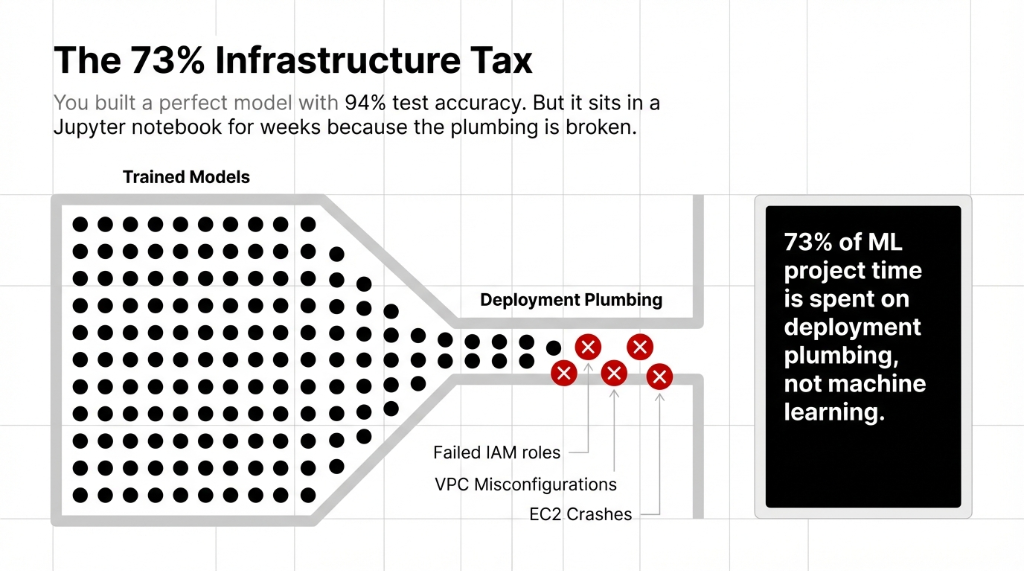
The SageMaker paradigm is built specifically to annihilate deployment dev-ops burdens. You upload model artifacts. You define scaling rules. AWS isolates and manages the underlying kernel instances identically.
The Unified MLOps Architecture Blueprint
Our standard machine learning operations pipeline turns data aggregation directly into self-healing endpoints. Let's look at the actual blueprint our developers deploy.
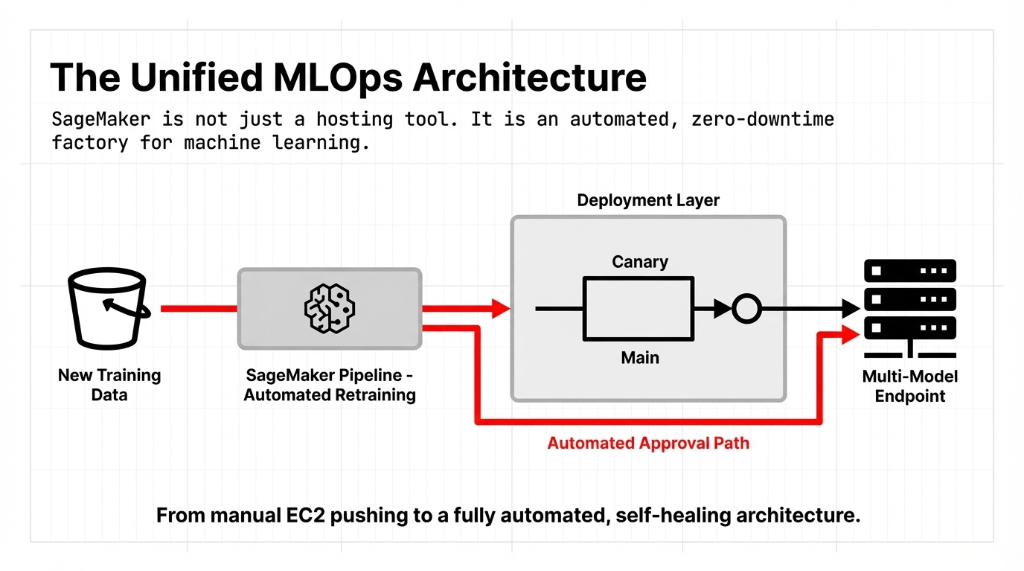
You need automated retaining directly triggering model endpoint swaps. SageMaker handles zero-downtime updates aggressively without routing adjustments needed by your team.
The Execution Cost Hack Everyone Ignores
The Multi-Model Shift
Stop paying $280/month for each individual endpoint. Multi-model endpoint features allow you to attach 100 separate models to exactly one endpoint. Cost drops 94% instantly.
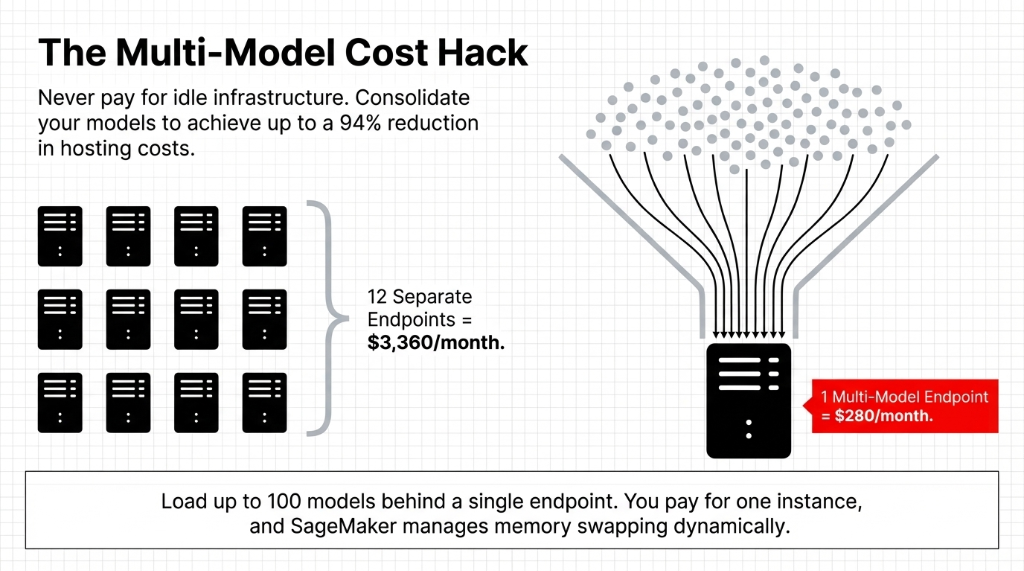
Do not choose real-time deployment arbitrarily. If you run batch inferences for business operations nightly, you are paying 24 hours of uptime for 30 minutes of deep learning modeling compute. Use batch transform.
SageMaker Pipelines and Canary Safety Rules
Pushing machine learning models without an active safety switch is amateur architecture. Use Canary testing in production.
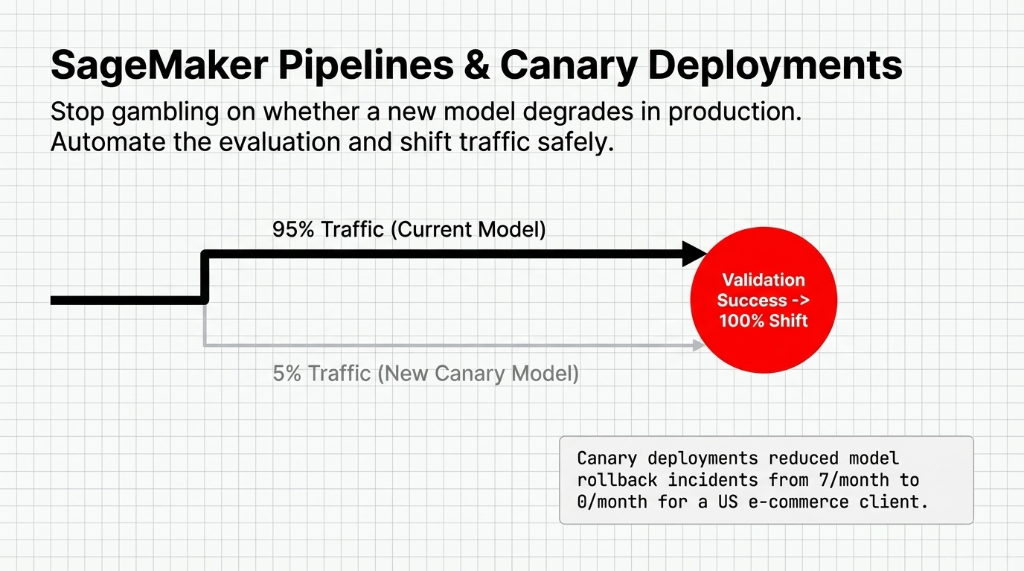
Canary routing aggressively filters 5% of direct volume toward the new pipeline, testing live metrics before fully 100% migrating. If anomalous performance spikes execute, AWS instantly reverts traffic back. This dropped our e-commerce client's deployment incidents strictly from 7 per month to absolute zero.
The Execution Facts
What Broken Plumbing Will Actually Cost You This Year
$18,400/year Engineering Drain
Two engineers generating custom manual model deployment scripts waste nearly 100 hours each.
$9,200/year Incident Responses
Emergency manual patching and troubleshooting when environments drift and fail quietly.
$31,000 Expected Downtime Impact
A 4-hour breakdown taking dynamic pricing offline permanently loses capital.
The demo covers an end-to-end workflow: train the model, upload it to S3, configure the inference instance, and successfully process production calls instantly without Docker build conflicts.
FAQs
What is SageMaker model deployment and how does it work?
SageMaker model deployment is taking a trained machine learning model and hosting it on a managed AWS inference endpoint. AWS handles all underlying server management, health checks, and scaling.
How long does it take to deploy a model on AWS SageMaker?
A standard endpoint deployment takes 5–10 minutes. Larger models (10GB+) may take 20–30 minutes. Serverless Inference deployments are faster but incur a 200–500ms cold start.
What is the difference between SageMaker real-time endpoints and batch transform?
Real-time endpoints serve individual predictions with under 100ms latency and are billed by the hour. Batch transform processes large datasets in bulk, is billed per job, and is 60–80% cheaper.
How much does it cost to run a SageMaker model deployment?
A basic ml.m5.large instance costs ~$84/month running 24/7. Serverless Inference for startups under 5 million invocations usually costs under $50/month.
Can I deploy multiple machine learning models on one SageMaker endpoint?
Yes. SageMaker supports multi-model endpoints (MME), letting you load hundreds of different trained machine learning models behind a single endpoint, reducing infrastructure cost by up to 94%.
Stop Bleeding Your AI Engineering Talent
Your team shouldn't be writing scaling health-checks in 2026. Watch our SageMaker operations demo to understand the exact mechanics, or skip the hassle entirely and let us build your deployment pipelines correctly from day one.