Most US companies spending $40,000–$200,000 a year on aws ai services are running the same mistake: they bought a platform for AI, not a solution for their business. They're paying for amazon sagemaker licenses, spinning up generative ai models they found in a marketplace, and then wondering why their ai app fails in production.
We've seen it 47 times in the last two years alone, across companies in fintech, healthcare, retail, and logistics — all scaling between $5M and $80M ARR. The problem isn't AWS. The problem is buying tools without a plan, then patching the gaps with more tools.
Here is exactly how we deploy an enterprise-grade ai application that actually works.
The AI Stack Most Companies Are Running Right Now
Walk into most mid-sized US operators and you'll find a patchwork. There's a cloud ai deployment that nobody fully owns. Three disconnected ai tools from different vendors. A fine-tuned llm model someone's data team set up in 2023 and never touched since. The result is a Slack channel called "#ai-stuff" where engineers escalate broken ai agents every Tuesday.
The Fake AI Strategy Problem
Hidden cost: $280,000 wasted annually on compute and overlapping tool subscriptions without achieving business impact.
A study cited by Telecom Advisory Services found that cloud-enabled aws and ai services will add massive value globally. The companies collecting that value aren't the ones buying seats on every ai platform available. They are the ones who picked 2–3 tools, deployed them deep, and measured every output.
We built our three AWS AI packages specifically because we got tired of watching clients burn capital on advanced ai that solved the wrong problems.
Why Generic AI Models Fail Enterprise Use Cases
Here's the ugly truth nobody in the ai landscape wants to say out loud: most off-the-shelf generative AI models weren't trained on your data, your terminology, your customer behavior, or your compliance constraints. They hallucinate wildly.

If you use a general-purpose llm ai to answer patient queries in healthcare, that model has never seen your payer contracts or your intake workflows. It gives answers that are technically coherent but operationally wrong. In regulated industries, that's a legal liability, not just bad UX.
Choosing the right retrieval algorithm beats paying for a larger llm model every single time. Optimized RAG outperforms brute-force context stuffing. This is why we structure our implementations strictly around our three core deployment models.
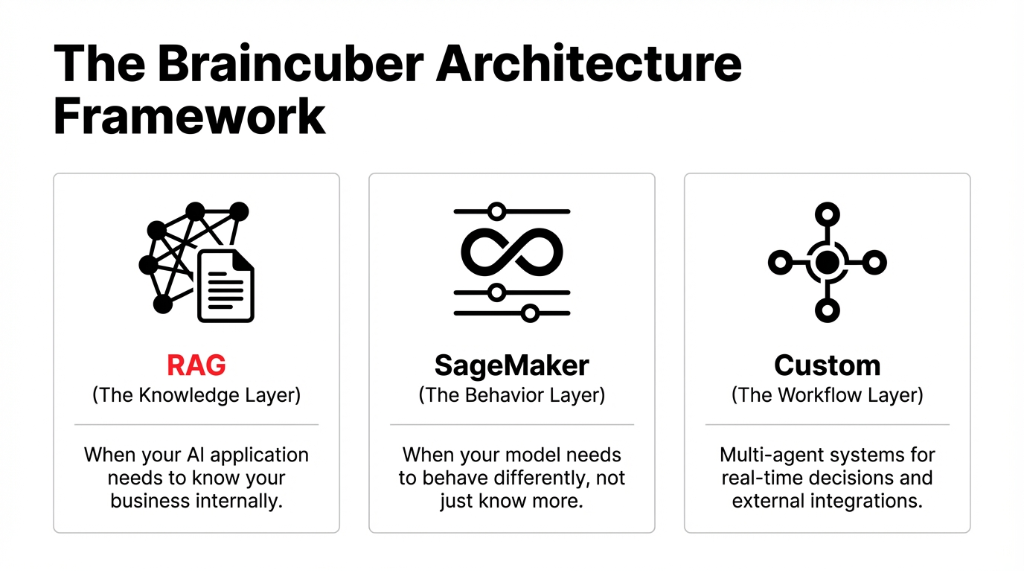
Package 1: RAG — When AI Needs to Know Your Business
Retrieval Augmented Generation is what you deploy when you need an AI that answers questions based on your internal knowledge — not what a foundation model learned from Reddit. Your corporate documents, SOPs, and customer histories get vector embedded.
We deployed this for a $12M logistics company. Before RAG, their support team spent an average of 14.3 minutes per ticket searching for documentation. After our RAG build on AWS, ticket resolution dropped to 2.1 minutes.
RAG Implementation Impact
Outcome: Massive efficiency gains for an overburdened service department.
Cost Savings at Loaded Labor Rate
Total: $91,200/Year
What this package includes from us is a full knowledge base architecture, vector store setup on AWS (S3 Vectors or OpenSearch), and an agentic RAG pipeline with LangChain orchestration. It's built for those who need secure AI solutions that don't invent facts.
Package 2: SageMaker — Build and Fine-Tune
If RAG isn't enough, you need a model that behaves differently, not just one that knows more. This is where aws sagemaker becomes your core build environment. We force strictly controlled MLOps discipline from day one.
Most companies developing ai set up a training job, deploy a model, and call it done. Six months later, the model drifts, performance degrades, and revenue drops. We implement automated training pipelines, parameter-efficient fine-tuning (PEFT), and rolling deployments with CloudWatch rollback triggers.
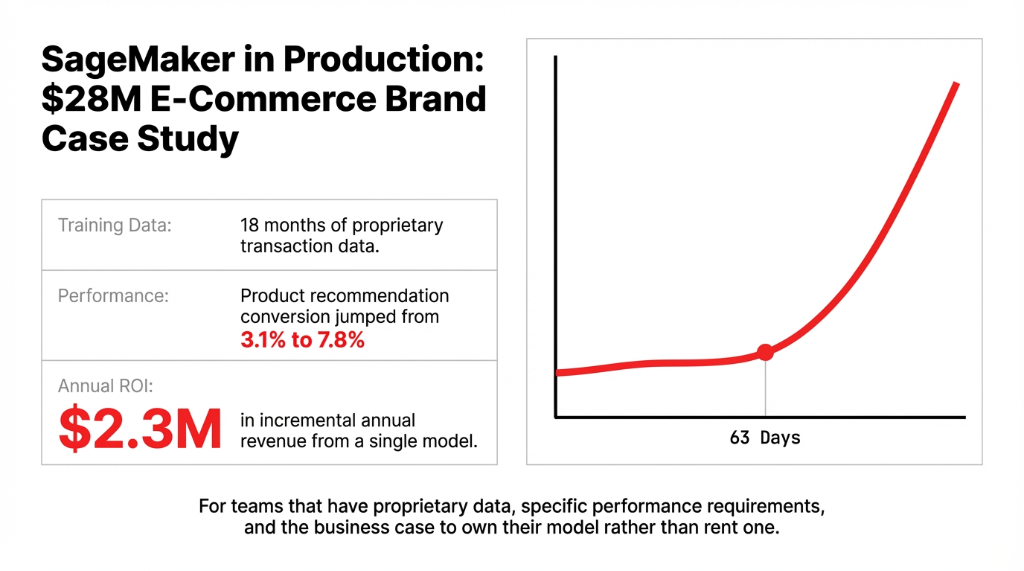
SageMaker Fine-Tuned E-Commerce Results
Conversion Lift
Jumped from 3.1% to 7.8% in 63 days.
Incremental Revenue
Generated $2.3M annually from one model.
This package is exclusively for scaling operations that have proprietary data and need to build an AI e-commerce edge they fully own, rather than rent.
Package 3: Custom AI Multi-Agent Workflows
Some problems do not fit a neat vendor template. We see this heavily with external integrations, real-time decisions, and ai application development that manages business logic outside the boundaries of a single model.
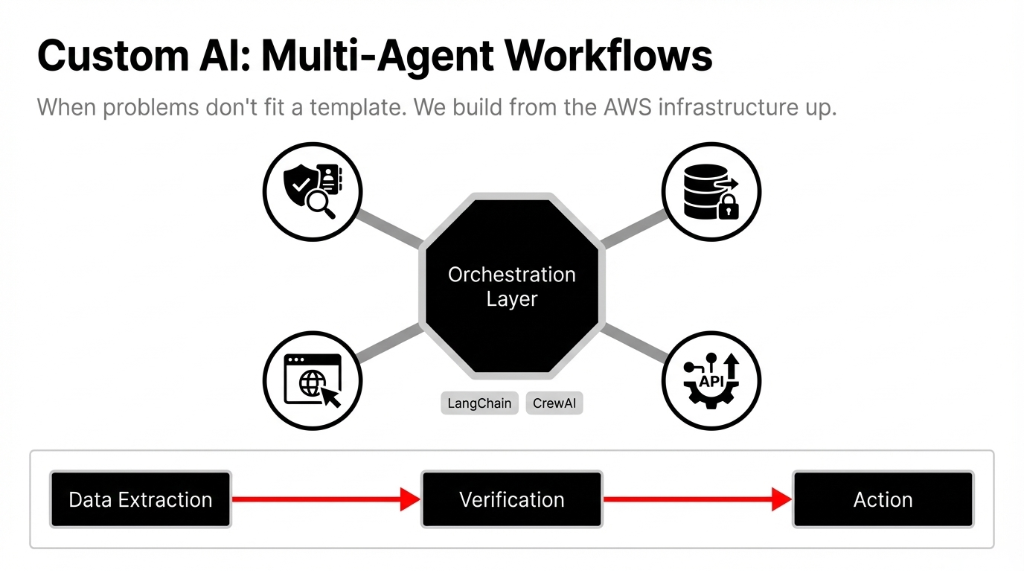
Custom managed ai means we build an orchestrated system from the AWS infrastructure up. We connect specialized LangChain or CrewAI agents to extract specific data, verify compliance constraints, and trigger production actions — completely bypassing human bottlenecks.
This level of custom automation acts as a comprehensive cloud consulting service, completely transforming your back-office execution speed.
Frequently Asked Questions
How much do your AWS AI packages cost?
Projects typically range from $18,500 to $45,000, recovering their cost within 3-4 months by cutting manual labor and saving wasted compute.
What is the difference between RAG and fine-tuning an LLM?
RAG retrieves correct data from your private documents. Fine-tuning adjusts the model's actual behavioral profile for highly specific outputs and decisions.
How quickly can you deploy a custom generative AI model?
A standard RAG pipeline deploys in 3 to 5 weeks. Complex Amazon SageMaker fine-tuning models take 6 to 9 weeks into production.
Do I need to migrate entirely to AWS for this?
No. We build the AI layer on AWS SageMaker and connect it smoothly to your existing workflows via secure APIs.
Are your AI solutions compliance ready?
Yes. Built natively inside AWS security infrastructure, your proprietary data never leaks out to train public internet models.
You are wasting $20k+ on generic LLMs.
Stop paying for AI that hallucinates when your team asks a simple question. Look at your monthly AWS bill. If it doesn't align with measurable revenue or drastically reduced labor hours, you have a problem. We will find it in 15 minutes.