Let's be brutally honest about the state of ai for companies right now. The latest in AI statistics are grim. According to IDC, for every 33 AI projects a company launches, only 4 ever go live. The average enterprise AI project has nearly double the failure rate of traditional IT.
We see the same pattern constantly. A manufacturing firm in Ohio spends $147,000 building an ai agent for predictive maintenance on AWS. The demo in Week 6 is flawless. Then the system hits their actual production data pipeline—an aging OSIsoft PI historian with three years of inconsistent sensor naming conventions—and hallucinates on 31% of readings within 72 hours.
Six months later, the $147,000 is gone. The ai system is shelved. This is not an AWS problem. It's a failure of most ai consulting companies who ignore the gap between a clean demo environment and real, messy business data. We have shipped 47 live AI systems to AWS production in the last 18 months. Here is exactly how we do it.
Week 1: Run the Data Reality Audit Before Writing Code
Here is the uncomfortable truth about ai applications running in enterprise environments: the POC only worked because someone heavily curated the data.
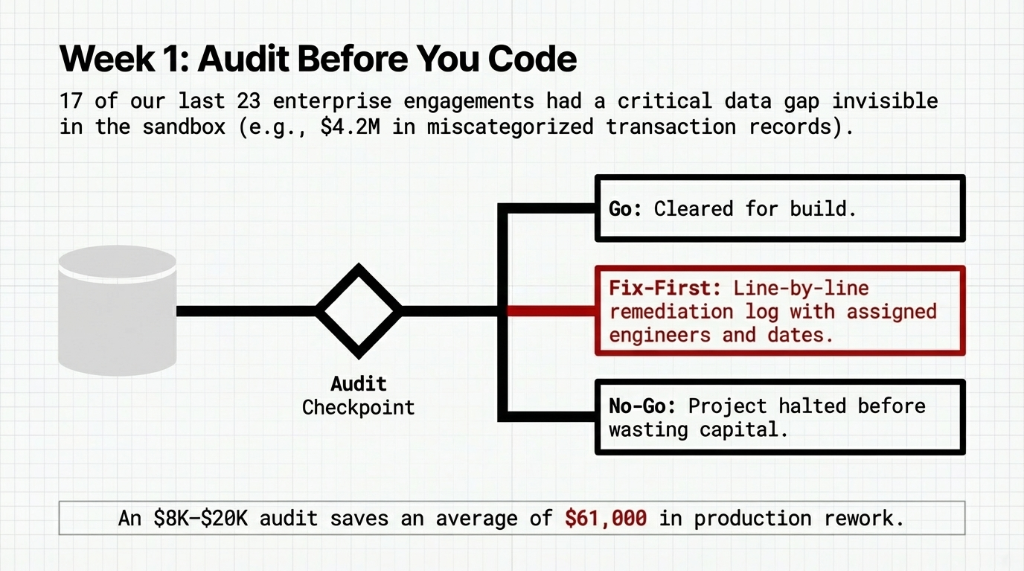
In Week 1, we connect directly to the actual source systems your ai model will run against—whether that's a Snowflake warehouse or a Salesforce CRM with 7 years of inconsistent fields. In our last 23 engagements, 17 had at least one critical data gap that would have broken the deployment within 30 days.
The Production Data Disaster
Hidden block: A finance AI use case had $4.2M in historical transaction records tagged with the wrong category codes. Invisible in the sandbox, catastrophic in production.
Our audit outputs a hard decision: Go, No-Go, or Fix-First. If it's Fix-First, we deliver a line-by-line remediation log with assigned engineers. An $8,000 audit saves an average of $61,000 in production rework. You cannot skip this assessment and expect a live system.
Week 2: Build Against Production Constraints, Not Lab Conditions
Most internal ai developer teams build their POC in a clean sandbox. No authentication layers. No rate limits. No concurrent users. That is exactly why it always breaks when you try to scale it.
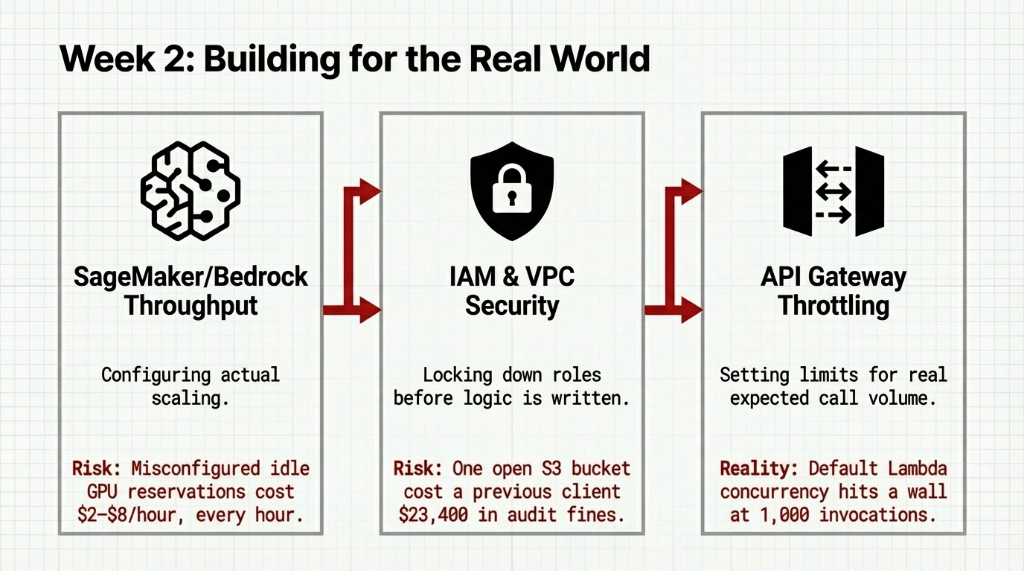
In Week 2, we harden the architecture against the exact constraints it will face on AWS. We configure SageMaker and Bedrock endpoints with actual throughput requirements because misconfigured idle GPU reservations cost $2 to $8 per hour, every hour you don't need them.
The Compliance Cost of Missing Constraints
S3 Security: Locking down IAM roles before business logic is written.
Cost of a Single Open Bucket
Paid Audit Fines: $23,400
When your ai chatbot goes live handling 3,000 conversations a day, default Lambda limits hit a wall at 1,000 concurrent invocations. We set API Gateway throttling at the real expected call volume on day one.
Week 3: MLOps and the Metrics Nobody Wants to Build
This is the week most firms skip because it doesn't look impressive in a demo. Intelligent automation with no observability layer is not production—it is just a scheduled incident waiting to happen.
We build the full ai ml operations layer on AWS using SageMaker Model Monitor and CloudWatch dashboards. The dashboards track business metrics, not system metrics. A CEO does not care about EC2 CPU utilization; they care if the ai for business use case is producing outcomes that map to cost reduction.
Observability Impact Data
Monitored MLOps
Caught model degradation in 3.7 days on average.
Unmonitored MLOps
Average time to detection hit 34 days, destroying revenue.
If you want to scale cloud infrastructure safely, alerting pipelines to PagerDuty or Slack must exist when model confidence drops below 87%.
Week 4: Phased Rollout — Fipping a Switch Breaks Production
The biggest mistake in ai implementation across companies is going from 0% to 100% live traffic on launch day. Stakeholders want to see it working now, but flipping the switch breaks production immediately.
We run a structured rollout: Shadow Mode for Days 1–4, Assisted Mode for Days 4–10, and Autonomous Mode for Days 10–28. In Shadow Mode, we measure the agreement rate between AI recommendations and human decisions. We mandate above 91% agreement to proceed.
In Assisted Mode, the artificial intelligence agent recommends, and humans approve. This one step cuts employee pushback on adoption by 63%. Real ai e commerce and finance projects fail culturally far more often than technically.
Live Phased Rollout Outcomes
Finance AI: Invoice processing dropped from 4.2 minutes to 38 seconds. At 1,400 invoices per month, that recovered $14,700/month.
Manufacturing Maintenance Saved
$83,400 Avoided Downtime by catching 3 failures early.
The Uncomfortable Truth About Pilot Purgatory
The aws ai stack is incredibly mature. The tech isn't the bottleneck. The bottleneck is dirty data, lack of defined success metrics, and poor change management. You cannot do real artificial intelligence integration without owning the business process it replaces.
If your POC has been running for 8 weeks with no production date, and nobody can name the exact dollar figure it is meant to move, you are running an expensive experiment with no exit ramp. We pulled 11 stalled projects out of purgatory in 14 months, averaging 23 days to live AWS production.
Frequently Asked Questions
How long does it realistically take to go from AI POC to AWS production?
For a well-scoped single use case with clean data and a defined success metric, 4 to 6 weeks is achievable on AWS. Vague scopes usually drag this out to 4–6 months. Our process compresses that timeline tightly.
Why do most AI POCs fail to reach production?
88% fail because the lab data doesn't reflect actual messy constraints, there is no real ROI metric set, and the agency completely skips MLOps and security scaling steps.
What does a production-ready AI system on AWS actually cost?
Usually between $28,000 to $67,000 for the build, saving tens of thousands in manual waste and totally eliminating $147,000 lost POCs.
What AWS services are actually used in a production AI deployment?
The core stack heavily relies on SageMaker for models, Bedrock for GenAI, Lambda and API gateway for endpoints, tightened with strict IAM identity bounds.
How is Braincuber different from other AI agencies?
We do not build demos. We build measured, heavily audited production deployments defined by cost recovered or revenue gained, not by novelty algorithms.
You are running an expensive experiment, not a strategy.
Stop letting your AI POC collect dust while paying cloud bills for unused test environments. If you cannot name the exact dollar figure your AI deployment will move, you are in pilot purgatory. We will find your exact blocker in 15 minutes.