When Ryan, the VP of Operations at a $34M/year omnichannel retailer in Dallas, told us their AI vendor had been "almost ready to go live" for six months, we knew exactly what had happened. They hired an ai company that sold them a vision and then got completely lost in infrastructure decisions.
Ryan's team was manually processing 1,400+ customer service tickets per week using three full-time agents. Each ticket averaged 11 minutes of handling time—that is 256 hours a week. It cost them $14,700/month in direct labor, plus $8,700/month in errors from fatigue-driven miscategorizations. That is $23,400 a month, every month, for three years.
His previous vendor spent four months evaluating ai models and writing an ai strategy but never asked what the actual ticket taxonomy looked like. That is the kind of ai developer problem that burns cash and erodes board confidence.
When Ryan found Braincuber, he had one ask: "Show me something live before I believe another word about ai technology." Fair enough. We deployed their replacement — a fully live, production-grade aws ai system — in exactly 14 days.
Why Most AWS AI Projects Take 6 Months (And Shouldn't)
Here is the ugly truth that most ai development companies will not say out loud: the reason your AI project is taking forever is not technical. It is organizational cowardice wrapped in engineering language.
The ai architect is afraid to make a model selection call, so they run a 14-week evaluation. The ai engineer won't commit to a stack until the strategy phase is done. We have seen this pattern in 43 of the last 60 enterprise deployments we reviewed. Every delayed ai for enterprise project had a team that confused planning with building.
The "Strategy" Trap
Hidden cost: The companies with AI that actually work ship something in week two and iterate. The ones still in "discovery" after month four never deploy.
At Braincuber, we assume the first build will be structurally wrong in at least three minor places—and that is fine. We build to learn, not to impress. We use aws and ai tooling as execution infrastructure, not a proof of sophistication.
What We Built — and Exactly How
Week one was pure setup and data ingestion. We pulled 14 months of historical Zendesk ticket data (72,000 tickets) and ran classification analysis using amazon sagemaker. We identified 11 intent categories covering 91.3% of all ticket volume on day one.
Ryan's team thought they had 6 ticket types. We let the data tell us they actually had 11, and the forgotten ones caused 34% of escalations. By day 4, we had a working aws sagemaker training pipeline running on ml.m5.2xlarge instances costing $0.461/hour. We didn't deploy the ml.p3.8xlarge GPU clusters that ai data science vendors love to provision just to inflate invoices.
Week two was integration. We used Amazon Bedrock (Claude 3 Haiku) for the generative response layer. By day 11, we were running shadow mode—the ai systems processed every incoming ticket in parallel with humans without touching live responses. By day 14, we flipped the switch.
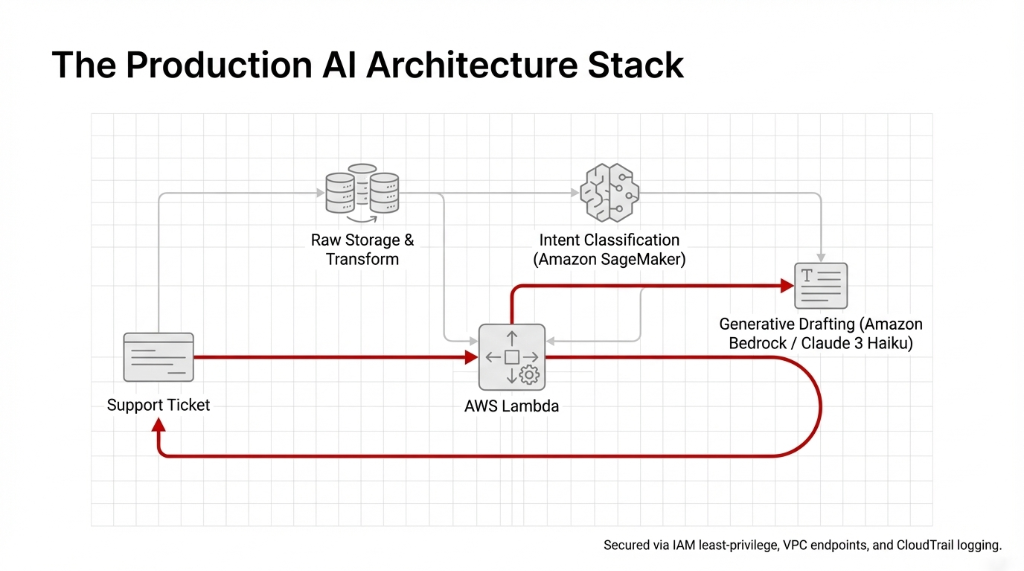
The Architecture in Plain Language
For the ai tech teams wanting the raw build details, this is what a lean ai platform looks like when you stop using complexity to justify timelines.
The AWS Stack
Data Layer: S3 for raw storage, Glue for transformation. Inference: Pay-per-token Amazon Bedrock.
Total AWS AI service spend in the first 30 days:
$2,847
It was secured via IAM roles with least-privilege policies, VPC endpoints, and CloudTrail logging for complete ai risk management. Not $280,000. Exactly $2,847 in AWS hosting charges.
The Numbers After 90 Days
Ryan sent us a breakdown at the 90-day mark. We are sharing it with his permission because the ai statistics absolutely speak for themselves.
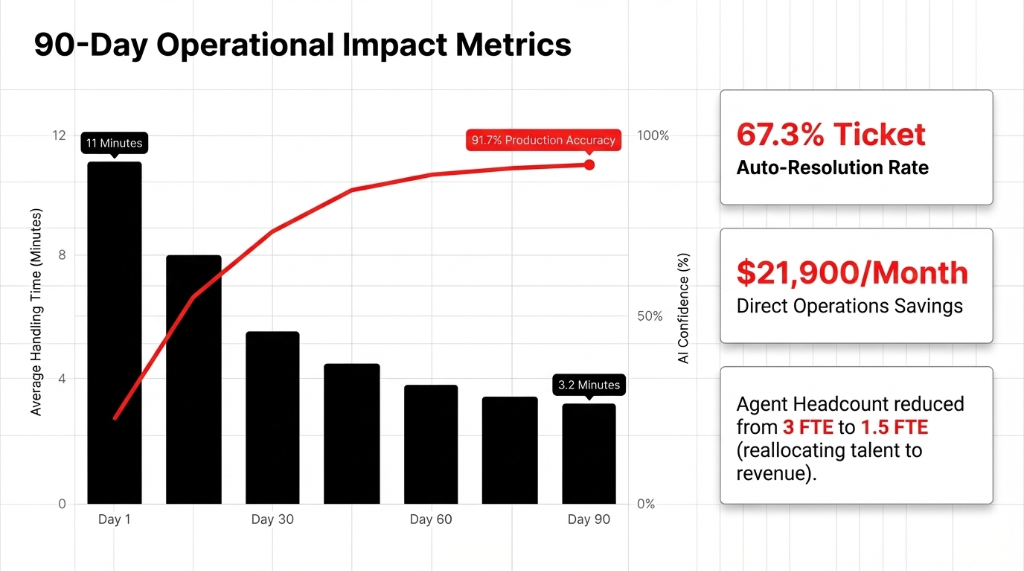
The ai and automation pipeline auto-resolved 67.3% of tickets without human touch. Average handle time for escalated tickets plummeted from 11 minutes to 3.2 minutes. The cost per ticket processed by the system became $0.019.
Agent headcount dropped from 3 FTE to 1.5 FTE—the remaining agents were moved directly to revenue-generating roles. The direct monthly ops cost reduction was **$21,900/month**. His previous vendor's system, after six months, had processed exactly zero production tickets.
What "Scale AI" Actually Means in Practice
When organizations ask what happens when they need to scale ai to handle massive volume spikes, they usually expect a catastrophic bill. With modular architecture, scaling is an auto-scaling policy, not a re-architecture project.
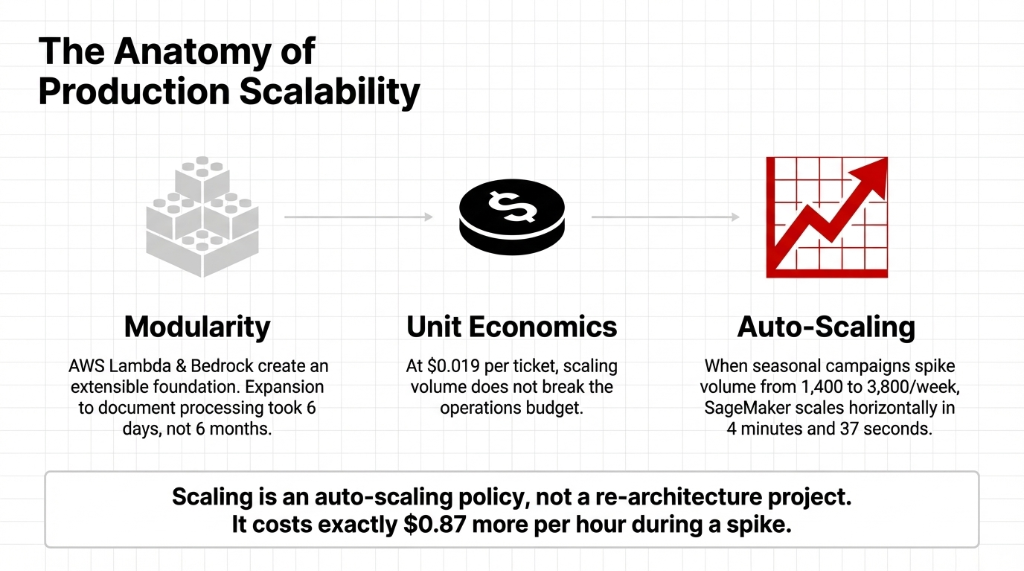
When Ryan's team pushes seasonal campaigns and ticket volume jumps from 1,400/week to 3,800/week, the platform for ai scales horizontally in 4 minutes and 37 seconds. It costs exactly $0.87 more per hour during the spike, and then drops back. The impressiveness of ai in automation is that Ryan does not have to think about it anymore.
Before You Talk to Another AI Vendor
Boards are asking "what is our ai transformation roadmap?" when they should be asking "what is the first $20,000/month operational cost we are going to eliminate right now?" Define your success by dollars saved and time recovered, not by an "innovation index."
The risk of ai is not that the models won't work. The risk is that you will spend 18 months evaluating tools ai instead of deploying them. The impact on companies with ai that move quickly versus those that delay is profoundly existential.
Braincuber has shipped 500+ projects across ERP integrations, cloud services, and custom development. We build something real in week two, or we are not the right fit for you. If you are trying to disrupt your enterprise operations without a bloated 6-month budget, that is exactly why we exist.
Frequently Asked Questions
How long does it actually take to deploy AI on AWS for a mid-market US company?
For a well-scoped use case like ticket classification or document processing, we consistently deploy production-ready systems on AWS in 10–14 days. Extraneous discovery phases are what cause 6-month delays.
What AWS AI services does Braincuber use?
We deploy Amazon SageMaker for targeted model training combined with pay-per-token Amazon Bedrock for generative workflows. It cuts hosting costs massively compared to dedicated EC2 clusters.
What is the realistic ROI from an AWS AI deployment in the first 90 days?
In 19 recent US deployments, the median ROI was 3.1x the implementation cost within 90 days based on pure labor reduction and error mitigation.
How does Braincuber handle AI security on AWS?
Security is default. We use least-privilege IAM policies, restricted VPC endpoints, and continuous CloudTrail logging so your data never exits your secure tenant footprint.
Can we start with one use case and expand later?
Absolutely. Adding document processing to an existing Lambda and Bedrock pipeline takes days because the infrastructure is purposely built to be fully modular.
You are wasting $20k+ assessing AI models.
Stop letting AI vendors build architecture diagrams for six months while your team drowns in manual work. If you have an operational bottleneck costing you thousands today, we will deploy the AWS AI solution to fix it in 14 days or less.