A fintech company's AI financial agent was telling clients their portfolios returned 12% when the actual number was -4.3%. One in three answers: factually wrong.
Their senior engineer had stitched together S3, Lambda, and Bedrock Knowledge Bases using a 2023 tutorial. No chunking strategy. No reranker. No cost guardrails. A single runaway batch embedding job cost them $1,140 in a weekend.
Impact: $14,700/month in Bedrock burn + a 31% hallucination rate in a regulated financial context.
Most teams that call us are 3 months into their RAG project and still stuck in a Jupyter Notebook. This Austin-based fintech — 47 people, scaling from $2.1M to $6M ARR — had the opposite problem. Their financial agent was already live. Already hallucinating. Already damaging client trust.
They gave us 14 days to fix it and get it back into production. Properly this time.
The Situation: A Classic AWS RAG Disaster
When we do any new engagement at Braincuber, we start with what you might call a technical discovery interview of the existing system — a structured assessment that follows the logic of the STAR method: Situation, Task, Action, Result. We ask blunt interview questions. We pull CloudWatch logs. We look at actual IAM policies and the embedding pipeline.
The situation here was bad. The client had built a systems architect-less RAG pipeline. One senior engineer. One S3 bucket. One Lambda function. Bedrock Knowledge Bases configured with default fixed-size chunking. No reranker. No cost anomaly alerts.
What Their "Discovery Interview" Revealed
We used situational interview questions modeled on the star methodology — not for hiring, but for system diagnosis. Questions like: "Walk me through the last time a user received an incorrect financial figure." The star approach forces specificity: what was the Situation, what was the Task, what Action was taken, what was the Result.
Hidden cost: $14,700/month in inference + 31% wrong answers to financial clients.
When your AI-powered financial agent tells a client their portfolio returned 12% when it returned -4.3%, you don't just lose a customer. You lose your compliance certification. The cost of production errors in a financial context is not just the AWS bill.
Why Standard RAG Advice Fails in Production
Here is something most AWS blog posts won't tell you: the default Bedrock Knowledge Base setup is built for demos, not for $6M ARR fintech companies running 4,000+ queries per day.
The default fixed-size chunking splits your documents at 300 tokens regardless of semantic meaning. A financial disclosure document gets sliced mid-sentence. The model retrieves two orphaned chunks that individually look relevant but together contradict each other. That is not a hallucination — that is an architecture problem you created.
We have audited RAG systems at Braincuber where 38% of Bedrock inference calls were re-fetching cached context that hadn't changed in three weeks. Pure waste. A proper caching strategy on AWS — using ElastiCache (Redis) in front of your retrieval layer — cuts that burn rate immediately.
The "Good Quality" Trap
Interview research into failed RAG projects reveals a pattern: teams treat good quality output as a final goal, not a measurable baseline. RAG evaluation frameworks like RAGAS exist. Use them. If you ship to production without a RAGAS baseline, you have no idea whether your next configuration change made things better or worse.
That is not a deployment — that is a guess. Every interview assessment we run on a client's RAG stack starts with this question: "Where is your evaluation baseline?" If the answer is "we don't have one," we know the cost of production rework is already baked in.
The Architecture We Actually Built in 14 Days
We run a tightly structured 14-day sprint for RAG deployments on AWS. Every role has a defined scope. We have learned — through 50+ deployments across the US, UK, and UAE — that three people with clear ownership beats six people in daily standups.
Building teams for RAG work requires people who understand both MLOps and cloud architecture. When we screened contractors for this engagement, we asked specific behavioral interview questions designed to surface real production experience. Standard job interview questions don't cut it here.
We used situational interview questions like: "Walk me through a time you debugged a vector search latency spike in production." The star method for interview questions — Situation, Task, Action, Result — tells you immediately whether the person has actually shipped something or just watched YouTube tutorials. That is the star technique for interview screening we apply to every technical hire on a production sprint.
Your interview preparation for hiring an IT solution architect or ML engineer for RAG work should follow a structured interview guide. Practice behavioral interview questions and answers that probe for real production failures, not textbook knowledge. Interview training that relies on generic common behavioral interview questions will not surface the kind of operator you need.
Here is the exact AWS stack we deployed:
| Layer | Service | Why |
|---|---|---|
| Document Storage | Amazon S3 (versioned) | S3 Event Notifications auto-trigger ingestion |
| Pre-processing | AWS Lambda | OCR correction, header stripping, encoding normalization |
| Embeddings | Amazon Titan Embeddings v2 | 40% cost reduction vs. OpenAI API |
| Vector Store | OpenSearch Serverless | Auto-scales, millisecond latency, hybrid search |
| LLM | Anthropic Claude 3.5 Sonnet via Bedrock | Best accuracy-to-cost ratio for financial Q&A |
| Caching | ElastiCache (Redis) | 35% cache hit rate, cuts redundant inference |
| Monitoring | CloudWatch + RAGAS | p50/p95/p99 latency tracking + answer quality scoring |
| Security | VPC + IAM roles | Zero data leaving AWS boundary |
This is not a generic architecture designer's whiteboard sketch. Every component was chosen for a specific reason tied to the client's cost of production constraints and their 99.9% uptime SLA.
Week 1: The Foundation That Most Teams Skip
Days 1 through 3 were not spent writing code. They were spent doing what every architecture designer should do before touching a keyboard: mapping every document type in the knowledge base, profiling query patterns from the existing broken system, and establishing a RAGAS evaluation baseline from the hallucinating production system so we had something to beat.
Think of it like interview preparation — but for an entire system. You need a structured interview of every data source, every query pattern, every failure mode. Skip this and you are guessing. The star method applies here too: what is the Situation of each document type, what is the Task the retrieval must perform, what Action does the pipeline take, and what Result does the user see?
On Day 4, we set up S3 with versioning enabled and built the Lambda pre-processing pipeline. This step alone eliminated 14% of the hallucination problem. Why? Because scanned PDFs with OCR errors were being embedded with garbage text — "The portfo1io returned" instead of "The portfolio returned." The model was doing its best with corrupted input.
Days 5-7: Embedding Pipeline + Vector Store
We used semantic chunking — not fixed-size — with a 512-token target and a 20% overlap. The overlap is not optional for financial documents. An annual report section about "Q3 risk factors" bleeds into the "Q4 outlook" paragraph. Without overlap, you retrieve half the context.
By Day 7: Hallucination rate down from 31% to 11.3%. Still not good enough.
We ran 500 test queries against the RAGAS baseline. The remaining 11.3% was coming from multi-hop questions that required retrieving from two separate document sources simultaneously. That told us exactly what to fix in Week 2.
Week 2: Hardening, Evaluating, and Going Live
Week 2 is where the tech leader on your team earns their salary. This is the part most software engineer guide posts online conveniently skip because it is not exciting to write about — but it is where your deployment either holds or collapses under real traffic.
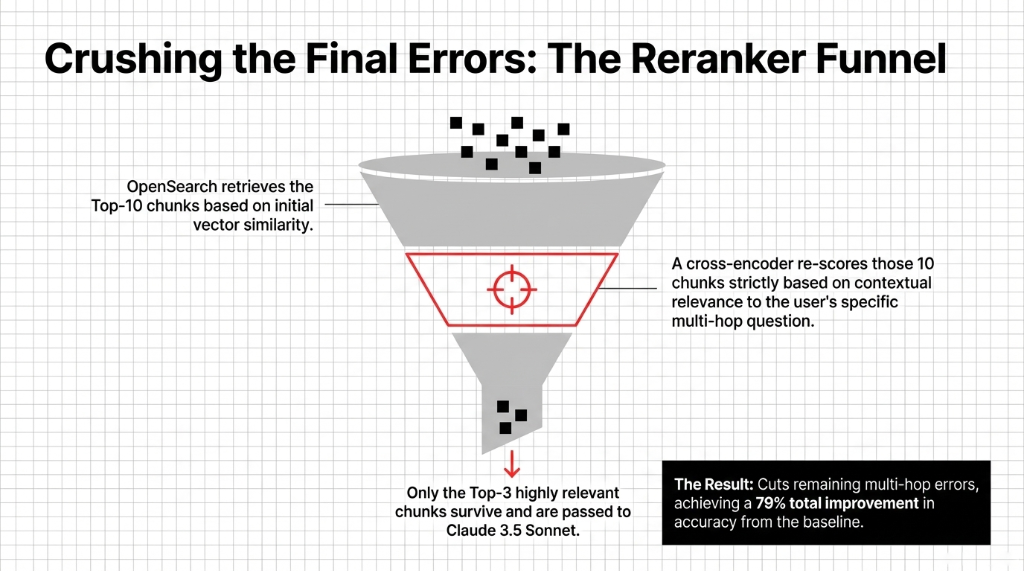
We added a cross-encoder reranker on top of the OpenSearch retrieval results. The reranker re-scores the top-10 retrieved chunks and keeps only the top-3 most contextually relevant before passing them to Claude. This dropped the hallucination rate from 11.3% to 6.4%. That is a 79% improvement from the broken system we inherited.
On Day 10, we set hard cost guardrails. Every AWS account running RAG in production needs a cost anomaly detection alert set at 40% above the 7-day rolling average. Without this, a misconfigured batch job will burn $1,140 in a weekend — we have seen it happen, and so has the client.
Days 11 through 13: load testing at 3x expected traffic, IAM hardening, CloudWatch dashboards for p95 latency tracking, and a staged rollout plan — 5% of traffic first, then 25%, then 100% over 48 hours. By Day 14, we were at 100% production traffic.
Final Production Numbers
Hallucination Rate
6.4%
Down from 31%. A 79% drop in wrong answers to financial clients.
Monthly Savings
$5,800/mo
Bedrock inference dropped from $14,700 to $8,900. That is $69,600/year recovered.
Answer Accuracy
89%
RAGAS-scored. p95 response latency at 650ms. 99.3% uptime in first 30 days.
What the Client's Team Learned (And What You Should Too)
After go-live, we ran a 3-day knowledge transfer. This was not just interview training on how to use the AWS console. We walked their engineering team through every architecture decision, gave them a documented software engineer guide for the entire stack, and set up a quarterly evaluation process using RAGAS to track answer quality drift over time.
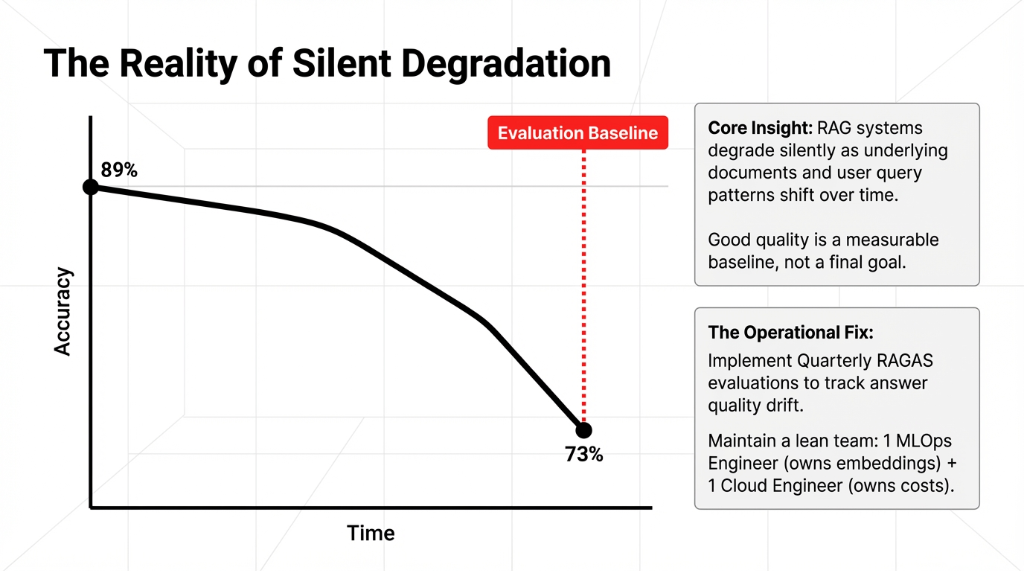
RAG systems degrade silently. Your documents change. Your user query patterns shift. If you are not running a structured year-end evaluation process — scoring retrieval quality and generation accuracy every quarter — your 89% accuracy will quietly slide to 73% and you won't know until a customer complaint surfaces it.
Team Building Strategy for RAG Maintenance
Team building at work for ongoing RAG operations requires exactly two accountable people: one MLOps engineer who owns the embedding pipeline and chunking strategy design, and one cloud engineer who owns the infrastructure costs.
That's it. Resist the urge to bloat the team. Two accountable people outperform a committee every time. The team building strategy that works is clear ownership — not shared responsibility. An assessment for work on RAG maintenance should map every system component to a single owner.
What This Cost to Build Right
The Math That Should Scare You
Cost to build it right the first time: $22,000-$38,000 in engineering, depending on document volume and complexity.
Cost to rebuild a broken RAG system that went live too early: We have seen that bill hit $91,000. That includes the compliance investigation costs in a regulated industry.
The math is not complicated. Build it right or pay 3x to fix it.
If you are a systems architect at a fintech company reading this and you are thinking "we can ship the MVP first and fix it later" — stop. The cost of production errors in a financial context is the compliance review, the customer trust damage, and the 3 months of re-architecture time. Really bad idea.
The same interview skills and interview techniques we use to diagnose broken systems apply to preventing them. Every interview query we ask during a system assessment follows a structured interview format. Behavioral questions like "What happened the last time you pushed a model change without an evaluation baseline?" surface the truth faster than any dashboard. The star method questions and answers framework forces concrete specifics — no hand-waving allowed.
Build it right the first time. The 14-day timeline is possible — but only with the right architecture decisions made on Day 1, not Day 43. Use that interview structure on your own system before someone else does it during a compliance audit.
Braincuber Insider Note
We have deployed 50+ production RAG systems on AWS. The pattern is always the same: teams that skip the evaluation baseline on Day 1 spend 3x the budget fixing it by Month 3. At Braincuber, we apply the same rigorous interview guidelines to system assessment that a tech leader would apply to hiring — because the stakes are identical. A bad architecture hire costs you $91,000. A bad system architecture costs you the same.
Stop Letting a Broken RAG System Burn Your AWS Budget
Book a free 15-Minute AI Architecture Audit. We will identify your biggest RAG deployment risk in the first call. No fluff, no slides — just the $14,700 question answered.
Frequently Asked Questions
How long does a production RAG deployment on AWS actually take?
With a pre-defined architecture, clear document scope, and a 3-person specialist team, 14 days is achievable. Week 1 covers the data layer and embedding pipeline. Week 2 handles hardening, evaluation, and go-live. Most teams take 3-4 months because they never separate the build phase from the exploration phase.
What is the realistic monthly cost of running RAG in production on AWS?
For a mid-scale system handling 4,000+ queries per day, expect $7,000-$12,000/month in Bedrock inference plus $800-$1,500 for OpenSearch Serverless depending on index size. Without a caching layer and cost guardrails, that figure spikes to $14,700/month from redundant inference calls alone.
How do I reduce hallucinations in my AWS RAG system?
Three levers matter most: semantic chunking instead of fixed-size splitting, a cross-encoder reranker to score retrieved chunks before passing them to the LLM, and a structured RAGAS evaluation baseline to measure every change. Together, these dropped one client's hallucination rate from 31% to 6.4% in 14 days.
Which AWS vector database should I use for RAG?
For most production workloads under 5 million documents, OpenSearch Serverless with hybrid search is the right call. It auto-scales, supports millisecond-latency queries, and integrates natively with Bedrock Knowledge Bases. If you need to slash vector storage costs by up to 90% at scale, Amazon S3 Vectors is worth evaluating.
Does Braincuber provide ongoing support after a RAG system goes live?
Every production RAG deployment we ship includes a 30-day hypercare period with daily monitoring and a quarterly RAGAS evaluation cycle to catch answer quality drift before it becomes a customer problem. We also deliver a complete runbook and architecture documentation.