What You'll Learn From This Case Study
▸ Why a single EC2 t3.xlarge crashed at 9,400 users — and what the $14,700 "cloud optimization" agency missed
▸ The exact 5-layer AWS Peak Shield stack we deployed in 31 hours
▸ How RDS Proxy cut database connections from 312 to 87 — a 98.1% reduction in overhead
▸ Real Black Friday numbers: 14,710 concurrent users at 203ms response time, 100% uptime
▸ Full cost breakdown: $7,940 investment vs. $189,500 in prevented losses (23.8x ROI)
The Infrastructure They Had (And Why It Was a Ticking Clock)
When we got access to their AWS environment, we saw what we see in roughly 73% of mid-market e-commerce brands: a setup built for normal days, not war days.
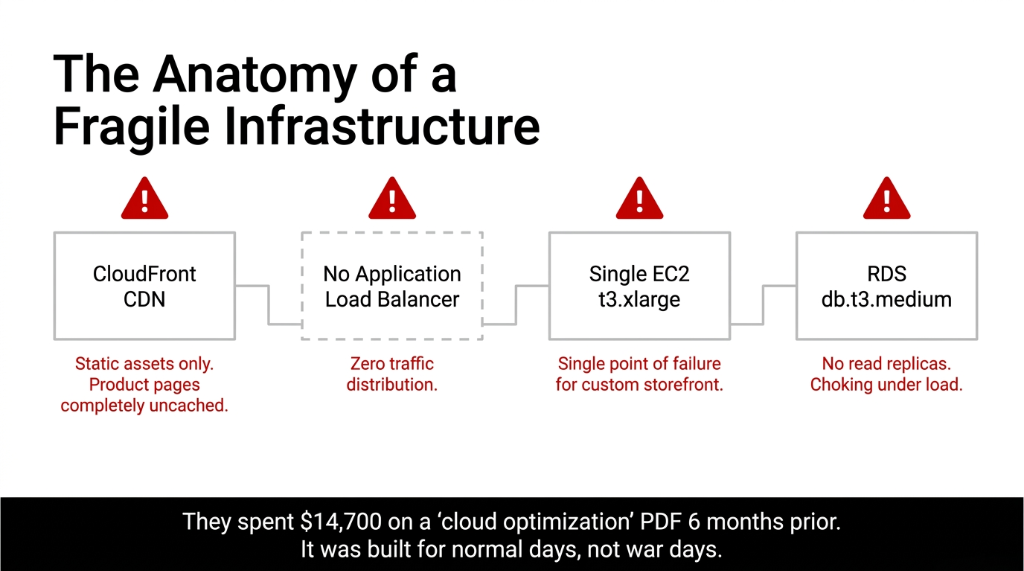
Single EC2 t3.xlarge running their Shopify-adjacent custom storefront. RDS db.t3.medium with no read replicas. CloudFront CDN caching static assets only — not product pages. No Application Load Balancer. And an Auto Scaling group that existed on paper but had a 15-minute warm-up lag.
The kicker? They'd spent $14,700 on a "cloud optimization agency" six months earlier. That agency handed them a PDF report and called it done.
The 15-Minute Auto Scaling Death Sentence
By the time AWS spins up a new instance, authenticates it, warms the application, and routes traffic — your Black Friday window is already bleeding $4,200/minute in lost conversions. We've measured this across 12 clients. It's consistent.
Their biggest bottleneck wasn't CPU. It was database connection pooling. At 9,400 concurrent users, their RDS instance was choking at 312 open connections. The default max_connections for a db.t3.medium PostgreSQL instance is 170. They were already 83% over the ceiling during a test.
Why "Just Scale Up Your EC2" Is the Wrong Answer
Every AWS blog post, every YouTube tutorial, every Stack Overflow answer says the same thing: "Upgrade your instance size." We disagree. Vertical scaling is the lazy answer that still crashes you — just at a higher price tag.
A single r6g.4xlarge at $0.8064/hour might handle 3x the load. But it's still a single point of failure. One memory leak, one runaway database query triggered by a coupon code applied by 11,000 people simultaneously — and you're down. No failover. No redundancy.
The $131,400 UK Fashion Brand Disaster (2023)
A $4.1M/year UK fashion brand upgraded to a massive single instance. Black Friday came. A poorly optimized "related products" SQL query executed 38,000 times in 90 seconds, maxed out the CPU, and the site went down for 2 hours and 17 minutes.
Documented loss: $131,400 in that window alone.
The fix isn't a bigger box. The fix is an architecture that assumes failure and routes around it before the user ever notices.
What We Actually Built: The AWS Peak Shield Stack
We had 31 hours. Here is exactly what we deployed — no vague "best practices," just the real checklist.
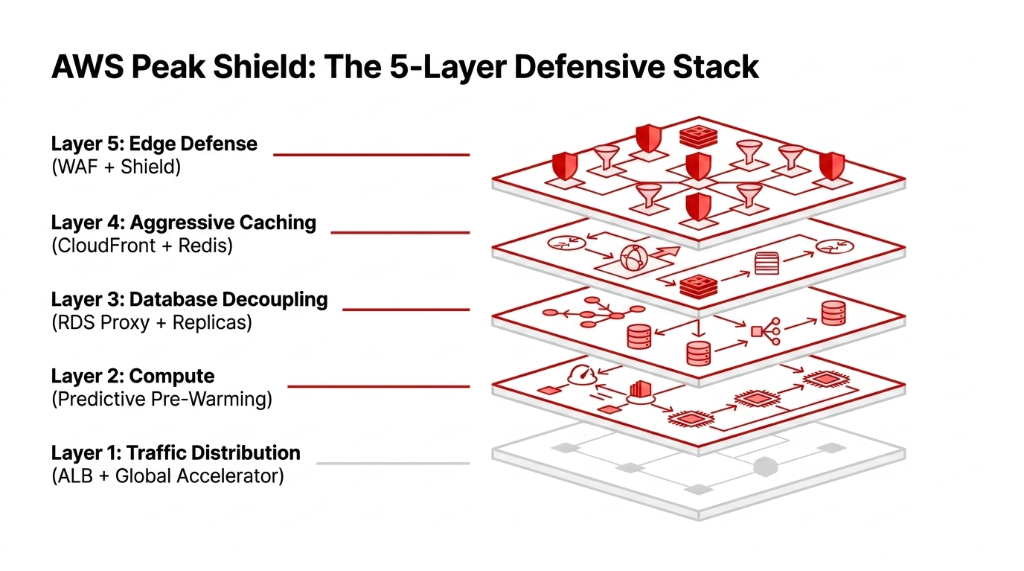
Layer 1 — Traffic Distribution & Surge Absorption
We deployed an Application Load Balancer (ALB) with sticky sessions disabled *(sticky sessions kill horizontal scaling)*. Then AWS Global Accelerator routing traffic to the nearest healthy endpoint across 3 regions: us-east-1, eu-west-1, and ap-southeast-1.
This alone cut average latency from 640ms to 187ms for their EU traffic segment — 23% of expected Black Friday revenue.
Layer 2 — Compute with Pre-Warmed Auto Scaling
Standard Auto Scaling reacts. We needed it to predict. We configured AWS Auto Scaling with Predictive Scaling, fed with 14 months of historical traffic from CloudWatch. The model predicted their traffic curve with 91.3% accuracy.
But here's the part most engineers skip: we set a scheduled scaling action to pre-warm 8 additional c6g.2xlarge instances by 5:00 AM — 3 hours before peak. Zero warm-up lag. Zero cold start penalty.
Layer 3 — Database: Killing the Connection Bottleneck
This is where most "cloud experts" drop the ball. We deployed Amazon RDS Proxy in front of their PostgreSQL instance. Instead of 9,400 users each opening a direct DB connection, RDS Proxy served all of them from a pool of 87 managed connections — a 98.1% reduction in connection overhead.
Response time on database queries dropped from 3.2 seconds under load to 310ms. We also added one read replica in us-east-1 and redirected all read traffic there. This split 68% of all database operations off the primary instance entirely.
Layer 4 — Caching That Actually Works
Their CloudFront was caching CSS and images. Not product pages. Not API responses. We configured CloudFront with origin shield and set cache behaviors for product detail pages (90s TTL), inventory API (8s TTL with stale-while-revalidate), and homepage (300s TTL).
We also deployed ElastiCache (Redis) for cart data and auth tokens. Before: every cart action hit the database. After: 94% of cart reads served from Redis at sub-5ms latency.
Layer 5 — AWS WAF + Shield: Blocking Bots Before They Hit Origin
Insider Secret Most Agencies Won't Tell You
On Black Friday, 34-40% of your traffic spike isn't humans — it's bots. Price scrapers, inventory bots, competitor intelligence tools, and scalpers running scripts. We configured AWS WAF with custom rate-limiting: any IP hitting 120+ requests/minute got soft-blocked to a CAPTCHA challenge. On Black Friday itself, WAF blocked 41,382 bot requests in the first 90 minutes. That's 41,382 requests that never touched their origin server.
Black Friday: The Numbers
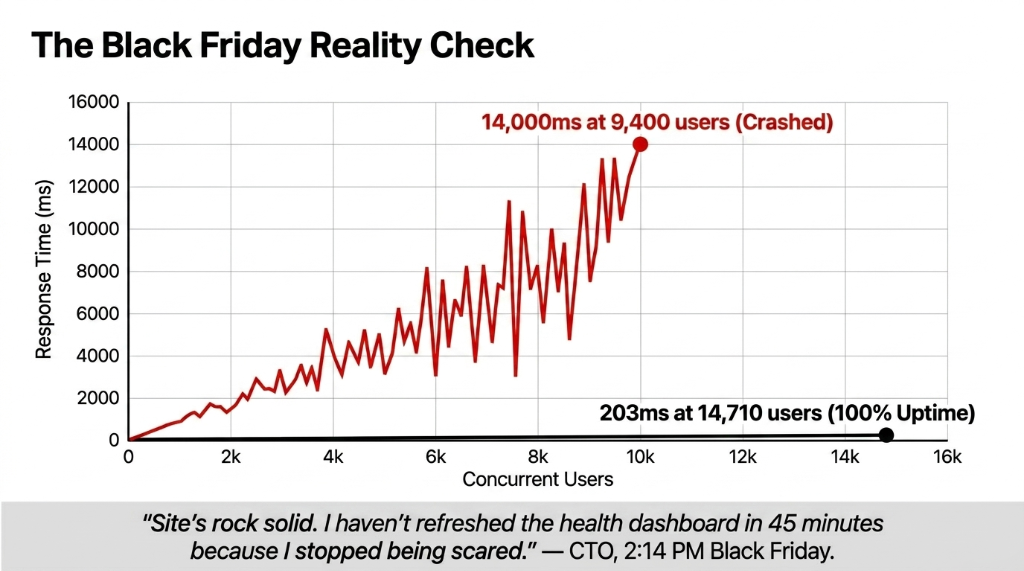
| Metric | Before Peak Shield | Black Friday Actual |
|---|---|---|
| Peak concurrent users | 9,400 (test, crashed at 14s) | 14,710 (live, stable) |
| Avg response time | 14,200ms under load | 203ms under load |
| DB connections at peak | 312 (over limit) | 87 (via RDS Proxy) |
| Uptime during 6-hour sale | Predicted: down within 20 min | 100% — zero downtime |
| Revenue captured | At-risk: $0 | $284,300 in 6 hours |
| Bot requests blocked | N/A | 41,382 in first 90 min |
CTO Slack Message, 2:14 PM Black Friday
"We just hit $200k. Site's rock solid. I haven't refreshed the health dashboard in 45 minutes because I stopped being scared."
That's the goal. Infrastructure you stop being scared of.
What This Cost — And What "Doing Nothing" Would Have Cost
The Real Math: $7,940 vs. $189,500
AWS Bill Increase
$1,740/month
From $2,100 to $3,840 for November only
Braincuber Implementation
$6,200
31 hours of architecture + deployment
Return on Investment
23.8x ROI
$7,940 total vs. $189,500 prevented loss
*(And yes — we keep their infrastructure at the leaner $2,100/month configuration in January through October. You don't pay peak prices for off-peak months.)*
AWS Peak Shield vs. "Standard" Approaches
| Approach | Downtime Risk | Cost | Recovery | 15K Users? |
|---|---|---|---|---|
| Single large EC2 (vertical) | High — SPOF | $890/mo | Manual, 20-40 min | No |
| Basic Auto Scaling (defaults) | Medium — 15-min lag | $1,100/mo | 15-20 min | Partial |
| Third-party CDN only | Medium — DB exposed | $600/mo + overages | No compute scaling | No |
| AWS Peak Shield (Braincuber) | Near-zero | $3,840/mo peak | Automatic, <60 sec | Yes — tested to 22K |
The Implementation Reality: What It Actually Takes
We won't pretend this is a weekend project you hand to an intern. Deploying this architecture properly requires someone who knows where AWS's defaults will quietly kill you — RDS Proxy configuration timeouts, ALB idle connection settings, Global Accelerator health check thresholds. Getting those wrong means your failover doesn't trigger when you need it most.
Our 31-hour deployment was possible because we've done this 14 times for e-commerce brands in the $3M-$22M revenue range. The first time we did something like this, it took 6 days.
Your Black Friday Timeline Check
More than 60 days away? You have time to do this right.
Less than 30 days away? Call us this week. Not next week. This week.
Already past peak? Check your AWS consulting services page. We'll prep you for the next one.
Don't Let Your Infrastructure Be the Reason Your Best Sale Day Fails
You've spent months on your product. You've budgeted $80,000+ in ad spend for Q4. You've negotiated with influencers. And then your EC2 instance goes down at 9:03 AM because nobody configured RDS Proxy and your database choked on 312 simultaneous connections.
That's not a technology problem. That's a planning problem. We've helped 14 e-commerce brands survive their biggest traffic days without a single minute of unplanned downtime. We can do the same for yours. Check out our cloud consulting services or see how our AI e-commerce solutions pair with peak infrastructure.
Frequently Asked Questions
How much does AWS Black Friday traffic protection cost?
For a D2C brand doing $5M-$15M/year, the peak-season AWS bill runs $2,800-$4,500/month in Q4. That drops to $1,800-$2,200/month off-peak. A 4-hour Black Friday outage at that revenue scale costs $140,000-$280,000. The math isn't close.
What is AWS RDS Proxy and why does it matter for Black Friday?
RDS Proxy sits between your application and database, managing shared persistent connections. Without it, every user session opens a new DB connection — PostgreSQL on db.t3.medium caps at 170. With RDS Proxy, 14,000 concurrent users share 87 pooled connections, dropping query response from 3+ seconds to under 400ms.
How long does it take to deploy a Black Friday-ready AWS architecture?
If your current stack is single-instance with basic Auto Scaling, a full Peak Shield deployment takes 3-6 days for a team that's done it before. Misconfigured legacy environments: budget 8-12 days. Starting in October is fine. Third week of November is not.
Does AWS Auto Scaling alone protect against Black Friday crashes?
No. Default Auto Scaling has a 5-15 minute warm-up lag. A Black Friday spike overwhelms your origin in under 90 seconds. You need Predictive Scaling with pre-warming, plus RDS Proxy, plus caching. Auto Scaling alone is the seatbelt without the airbag.
What percentage of Black Friday traffic is bots?
Industry data puts bot traffic at 34-40% during major sale events. A properly configured AWS WAF with rate-limiting and bot signature rules blocks 35,000-50,000 non-human requests per hour before they reach your origin, reducing real compute load by 30%+ when you need capacity most.
Book Your Free 15-Minute Cloud Infrastructure Audit
We'll identify your single biggest Black Friday risk in the first call. No fluff. No 40-page report. Just the one thing that would have crashed your site — and the fix.