If your Shopify orders, Amazon Seller Central payouts, and warehouse inventory data are still being reconciled in three separate Excel sheets every Monday morning, you are losing approximately $9,300 a month in analyst hours, delayed decisions, and SKU mismatches. We have seen this exact scenario play out in 47 e-commerce implementations. The fix is not hiring a third data engineer. The fix is building a proper ETL pipeline on AWS Glue - and doing it with security baked in from day one, not bolted on afterward.

The Data Mess Nobody Talks About
Here is the ugly truth about most e-commerce data stacks: they are not pipelines. They are duct-taped workflows.
A mid-size D2C brand doing $4M/year typically has order data sitting in Shopify, return data inside a Google Sheet, ad spend data locked inside Meta Business Manager, and fulfillment statuses scattered between ShipStation and a 3PL's FTP server. Every time your marketing analyst wants to calculate true ROAS by SKU, someone spends 6.5 hours manually joining these sources. That is $780 in labor cost for a single report - every single week.
Terrifying realization
Your "data pipeline" is a $9,300/month Excel surgery operation performed by people whose actual job is supposed to be optimizing ad spend and inventory turns.
Impact: $9,300/month
This is not a people problem. This is an architecture problem.
And the "standard advice" - spin up an EC2 instance, install Apache Spark, write custom PySpark scripts, manage your own cluster - is exactly the wrong answer for a brand under $20M ARR. You will spend $14,200 in the first year just keeping that infrastructure alive.
Why AWS Glue Changes the Math
AWS Glue is a fully serverless ETL service. No cluster to provision, no patching, no idle compute you are paying for at 2 AM. It connects to over 100 data sources natively - including Shopify via JDBC connectors, Amazon RDS, Amazon Redshift, S3 data lakes, and even your legacy MySQL databases still running on-prem.
Here is what the architecture looks like for a real e-commerce pipeline:
Extract
AWS Glue Crawlers scan your Shopify order exports in S3, your RDS transactional database, and your Amazon Seller Central reports - automatically inferring schema and registering metadata in the Glue Data Catalog.
Transform
Glue ETL jobs (written in Python or Spark) clean, normalize, and join the data. SKU-level deduplication, currency normalization for cross-border stores, return attribution - all handled in code that runs on Apache Spark under the hood.
Load
Clean, unified data lands in Amazon Redshift or S3 - ready for QuickBooks reconciliation, Tableau dashboards, or your Klaviyo segmentation queries.
The Billing Reality
Pay per DPU per second. A typical nightly pipeline processing 2 million e-commerce events costs approximately $1.47 per run at current DPU pricing.
Compare that to
A dedicated Spark cluster sitting idle 20 hours a day at $340/month. The math is not close.
The Security Layer Most Teams Skip (And Regret)
This is where 83% of e-commerce engineering teams leave a gaping hole. They build the pipeline. They forget to secure it.
AWS Glue operates in the AWS Security Deep Dives category for a reason - it touches your most sensitive data: customer PII, payment metadata, pricing margins, inventory costs. A misconfigured Glue job can expose all of it.
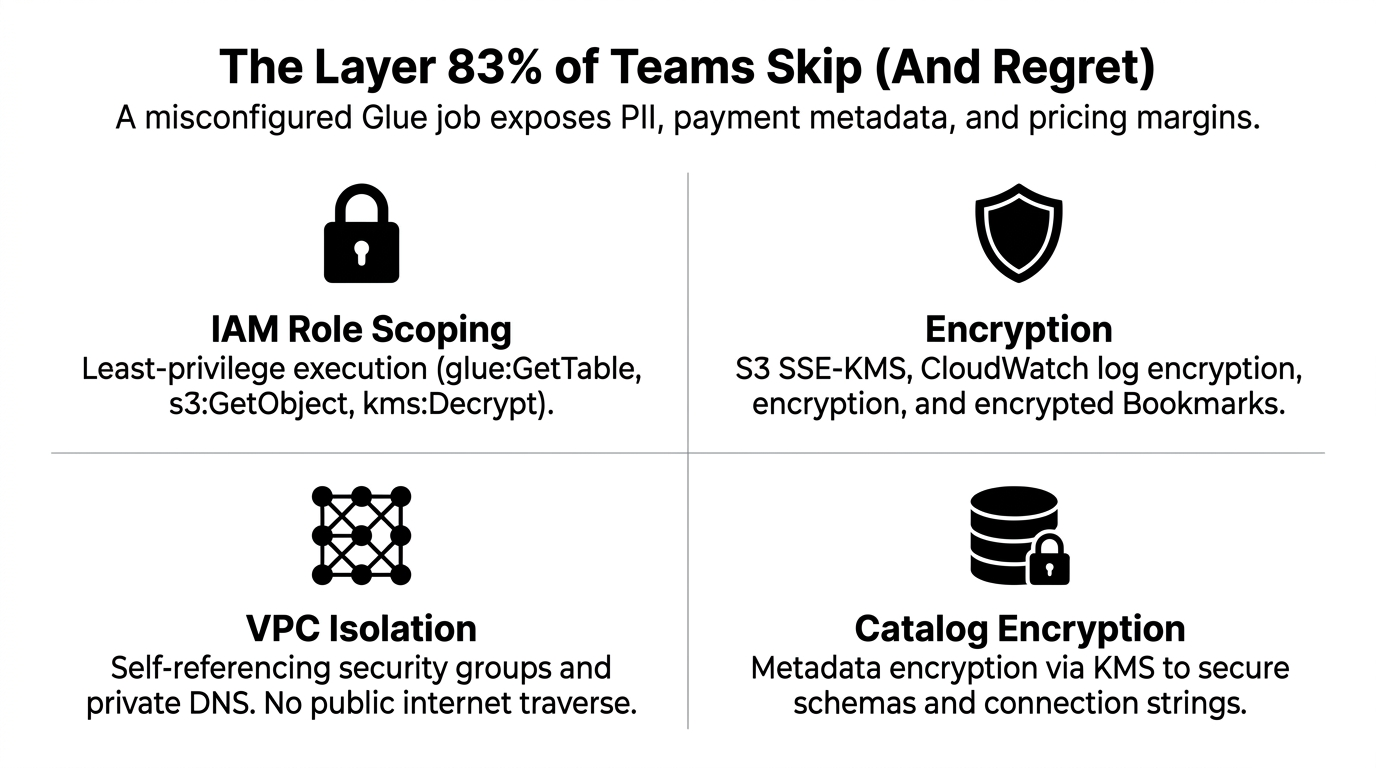
Here is what a production-grade security configuration actually looks like:
IAM Role Scoping
Every Glue job runs under an IAM execution role. The mistake we see constantly: teams assign AdministratorAccess to the Glue role because it "just works." That role can then read your entire AWS account. The right approach: create a least-privilege IAM policy that grants glue:GetTable, s3:GetObject on specific prefixes only, and kms:Decrypt for the exact KMS key used by that pipeline. Nothing more.
Encryption at Every Layer
AWS Glue Security Configurations let you enforce encryption at three levels simultaneously:
S3 Encryption (SSE-KMS)
All transformed data written to S3 uses your customer-managed KMS key - not AWS's default managed key, which you do not fully control.
CloudWatch Logs Encryption
Every job log is encrypted with a CMK. (Yes, logs contain SQL queries. Yes, SQL queries sometimes contain customer IDs.)
Job Bookmark Encryption
Glue bookmarks track which data has been processed to avoid reprocessing. Those bookmarks are written to S3 and must also be KMS-encrypted.
VPC Isolation
If your Glue jobs connect to RDS databases or JDBC sources, run them inside a VPC with a self-referencing security group rule. This ensures the Glue job and the database talk only to each other - no traffic traverses the public internet. Enable private DNS on your VPC endpoint so Glue resolves internal hostnames correctly.
Catalog Encryption
The Glue Data Catalog - essentially your metadata registry - stores table schemas, column names, and connection strings. Enable metadata encryption on the Data Catalog itself using aws/glue KMS key or a customer-managed key. Every new table registered by a crawler after this point is encrypted at rest.
Critical IAM Actions Required
The IAM permission set that opens up all of this requires six specific actions: glue:GetDataCatalogEncryptionSettings, glue:PutDataCatalogEncryptionSettings, glue:CreateSecurityConfiguration, glue:GetSecurityConfiguration, glue:GetSecurityConfigurations, and glue:DeleteSecurityConfiguration. If your Glue role is missing any of these, your security configurations silently fail to apply.
Building the E-Commerce Pipeline, Step by Step
We have implemented this architecture for brands shipping to the US, UK, UAE, and Australia. Here is the exact sequence that works:
Step 1 - IAM Foundation First
Create a dedicated Glue execution role. Attach only the S3 prefixes your pipeline needs. Enable MFA-protected access for humans who modify Glue jobs. This step takes 35 minutes and prevents 90% of data breach scenarios.
Step 2 - Raw Data to S3
Land all raw source data (Shopify webhooks, Amazon reports, 3PL CSVs) into a raw/ prefix in S3. Enable S3 Versioning and Object Lock on this bucket. If a Glue transformation corrupts data, you can roll back to the source truth.
Step 3 - Crawler Configuration
Point a Glue Crawler at your raw/ prefix. Set it to run on a 4-hour schedule during off-peak hours. The crawler infers schemas and populates the Glue Data Catalog - this is your single source of truth for what data exists and what shape it is in.
Step 4 - ETL Job Logic
Write your transformation job in PySpark using Glue's DynamicFrame API. For e-commerce, the three most impactful transformations are: currency normalization (critical if you sell in GBP, AED, and USD simultaneously), SKU deduplication (where a 0 instead of an O in your product code creates phantom inventory), and order-level return attribution (mapping refunds back to the original acquisition channel).
Step 5 - Load and Monitor
Load clean data into Redshift or an S3 processed/ prefix in Parquet format (Parquet queries run 3.7x faster than CSV in Athena at the same data volume). Set up Glue Job Bookmarks to process only new records - this cuts your DPU usage by 61% on daily incremental loads compared to full-scan jobs.
The Results You Should Actually Expect
Based on our implementations at Braincuber Technologies:
UK Fashion Brand
Processing 18,000 orders/day
Data reconciliation time
11 hours/week to 23 minutes/week
UAE Electronics Retailer
Multi-channel inventory sync
BI analyst overtime eliminated
$11,800/month saved
US Supplements Brand
Duplicate ad spend discovered
Hidden duplicate spend found
$3,200/month recovered
The pipeline fixed all three. AWS Glue did not "help" them grow. It stopped them from bleeding.
The One Thing That Will Kill Your Pipeline
Job Bookmarks. Specifically, teams who disable them "temporarily" during testing and forget to re-enable them in production.
Terrifying realization
When Glue Job Bookmarks are off, every job run reprocesses your entire historical dataset. For a store with 3 years of order history, that means processing 40+ million rows every night instead of just the 12,000 new orders from that day.
Impact: DPU bill jumps from $1.47/night to $58.30/night. That is a $1,700/month mistake hiding in a single checkbox.
Do not trust what your junior developer says when they tell you "the bookmark settings are fine." Pull the CloudWatch metrics yourself after every deployment. Check glue.driver.aggregate.recordsRead - if that number is consistently near your total record count and not near your daily delta, bookmarks are broken.
Connecting Glue to Your Broader AWS Security Posture
AWS Glue does not exist in isolation. In a properly architected e-commerce stack, it operates as part of a layered security model:
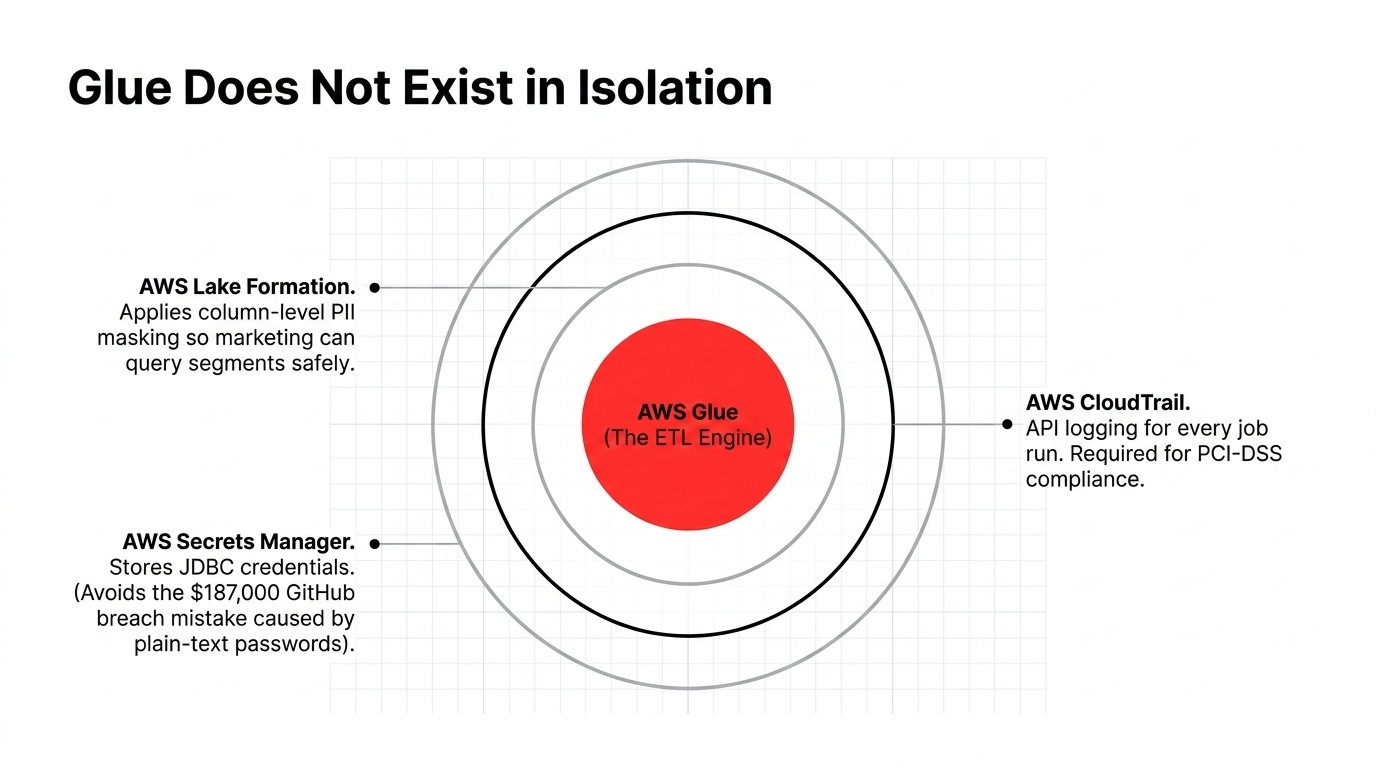
AWS Lake Formation
Governs column-level permissions on top of the Glue Data Catalog - so your marketing team can query customer segments without ever seeing raw PII like email addresses or phone numbers.
AWS CloudTrail
Logs every API call made by your Glue jobs - who ran what, when, and against which tables. Required for PCI-DSS compliance if your pipeline touches payment metadata.
AWS Secrets Manager
Holds your JDBC connection credentials. Never hardcode database passwords in Glue job scripts. We have seen a startup's entire customer database compromised because a developer pushed a Glue script to GitHub with an RDS password in plain text. The breach cost them $187,000 in breach notification and legal costs.
Stop Patching. Start Architecting.
You are not running a data engineering firm. You are running an e-commerce brand. The more hours your team spends debugging broken CSV imports and fixing VLOOKUP errors in Monday's revenue report, the fewer hours they spend on what actually drives growth.
AWS Glue, configured correctly with security-first architecture, turns a $9,300/month data operations headache into a $47/month infrastructure line item.
Stop Patching. Start Architecting.
Book a free 15-Minute AWS Architecture Audit with Braincuber Technologies. We will identify the exact point in your current data stack where money is leaking - and tell you precisely how to fix it. No pitch deck. Just your pipeline, our eyes, and a specific action plan.
Book Your Free 15-Minute AWS Architecture AuditWe have deployed secure, production-grade AWS Glue pipelines for brands from $1.2M to $48M ARR. We know what breaks, what to watch for, and how to prevent the $187,000 breach you have not had yet.
The Bottom Line
AWS Glue is not an ETL tool. It is a data operations rescue mission. If your e-commerce data is still duct-taped across spreadsheets, Shopify exports, and 3PL FTP servers, you are likely burning $9,300/month on manual reconciliation alone - before you even count the missed revenue from delayed inventory decisions and broken ROAS calculations. Get a free implementation roadmap tailored to your data sources, order volume, and compliance requirements at Braincuber.
Frequently Asked Questions
How much does AWS Glue actually cost for a mid-size e-commerce pipeline?
For a brand processing 500,000 to 2 million order events per day, expect $40 to $120/month using Glue's serverless DPU billing. Costs spike if Job Bookmarks are misconfigured or if your crawler runs on too-frequent schedules. With proper tuning, a daily incremental pipeline processing 12,000 orders runs under $2 per job execution.
Does AWS Glue work directly with Shopify?
Not natively out of the box. You need to first land Shopify data into S3 (via Shopify webhooks, a third-party connector like Fivetran, or AWS AppFlow) and then point Glue Crawlers at that S3 prefix. Attempting to query Shopify's GraphQL API directly from a Glue job is possible but introduces rate-limit failures that corrupt your pipeline during peak traffic periods like Black Friday.
How do you secure customer PII inside an AWS Glue ETL pipeline?
Three mandatory steps: enable KMS encryption on S3 targets via a Glue Security Configuration, run jobs inside a VPC to prevent public internet exposure, and enable Glue Data Catalog metadata encryption. For column-level PII masking (emails, phone numbers), integrate AWS Lake Formation permissions on top of the Glue Catalog before any downstream BI tool connects.
What is the difference between AWS Glue and running Apache Spark on EC2?
AWS Glue is fully serverless - no cluster management, no patching, no idle compute costs. Self-managed Spark on EC2 gives you more fine-grained tuning but costs $8,000 to $14,000/year more in infrastructure and engineering time for a typical e-commerce workload. Unless you are processing over 50 TB daily, Glue's managed Apache Spark engine is the better economic choice.
How long does it take to build a production AWS Glue pipeline for e-commerce?
A properly secured, production-ready pipeline connecting Shopify, Amazon Seller Central, and a Redshift data warehouse takes 3 to 5 weeks when done correctly - including IAM role scoping, KMS key configuration, VPC setup, transformation logic, and CloudWatch monitoring dashboards. Teams that rush it in 3 days skip the security layer and spend 6 weeks debugging it later.