Here is the ugly truth: according to Gartner, organizations waste up to 30% of their cloud spend—and in 2026, with aws generative ai workloads compounding that waste, the real number is closer to 40% for teams running artificial intelligence services without a real FinOps discipline in place.
If you have not cut your aws cost by at least 25% through deliberate architecture decisions, you are not scaling. You are bleeding faster.
The AWS AI Cost Drain Nobody Audits
The first mistake we find when auditing amazon console accounts at Braincuber is consistent: teams treat every prompt identically. A simple yes/no customer intent classification gets routed to Claude Sonnet. Then someone panics at the aws price report and blames traffic spikes.
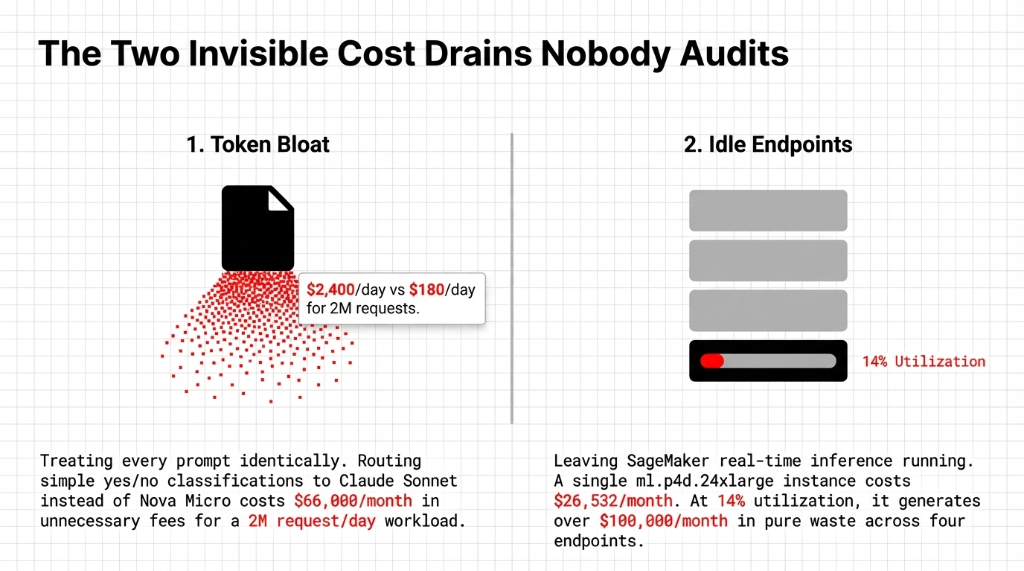
Token count is the single biggest cost driver in aws bedrock. If your ai platform runs 2 million requests per day, you are paying roughly $2,400 per day on a model that Amazon Nova Micro handles for $180 per day on the same use case.
The second invisible drain: idle SageMaker endpoints. We pulled a client's amazon cloudwatch dashboard that showed four ml.p4d.24xlarge endpoints running at 14% average utilization. That is over $100,000 a month in pure waste across four endpoints.
Why "Just Use Spot Instances" Is Only Half the Answer
The aws and cloud community loves this advice. And for aws ml training jobs, yes—Managed Spot Training delivers up to a 90% discount on compute.
But here is what the aws certification courses gloss over: Spot Instances do not fix your token bloat. They do not fix the fact that your RAG pipeline pulls 47 documents into context when 3 would answer the query. We have watched teams recommend Spot for everything, then wonder why production inference latency spikes 800ms during Spot reclamation events.
The 5-Layer AWS AI Cost Optimization Framework
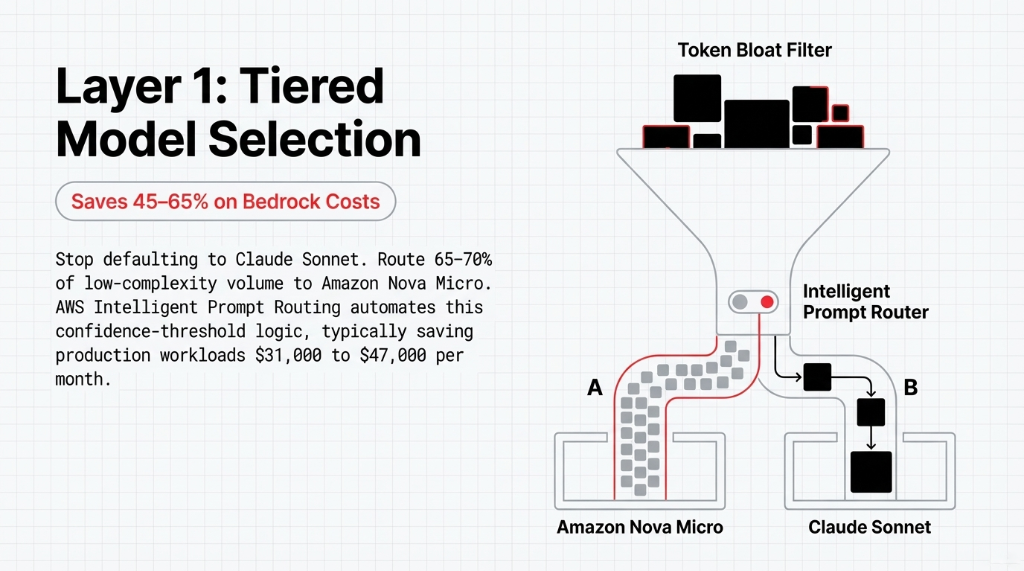
Layer 1: Tiered Model Selection — Saves 45–65% on Bedrock Costs
Route 65–70% of your total request volume to Nova Micro. Escalate to Claude Sonnet based on a confidence threshold, not by default. AWS's Intelligent Prompt Routing automates this logic, typically saving production workloads $31,000 to $47,000 per month.
Layer 2: Prompt Caching — Saves up to 90% on Repeated Inputs
If your cloud ai system sends the same 500 tokens of system instructions with every API call, you are paying full token price every time. AWS Bedrock's prompt caching stores the KV cache of repeated prefix tokens. Activating this recovers approximately $29,000 per month for a 2 million requests/day pipeline.
Layer 3: Batch Inference for Non-Real-Time Workloads — 50% Flat Discount
If you are running sentiment analysis across 10,000 product reviews every morning at 2 AM on on-demand aws bedrock, you are paying exactly double what you should be. AWS Bedrock's batch inference mode delivers a flat 50% discount on all tokens.
Layer 4: Multi-Model Endpoints — Cuts Hosting Costs up to 90%
Every separate SageMaker endpoint is a separate billing clock running 24/7. SageMaker Multi-Model Endpoints (MME) host hundreds of models on a single instance with shared memory management. One Braincuber client collapsed 11 separate endpoints into 1 MME configuration, dropping inference hosting from $31,400 to $3,900.
Layer 5: CloudWatch-Driven Right-Sizing — Continuous, Not Quarterly
If aws billing spikes more than 15% week-over-week on Bedrock or SageMaker, you want an alert within 4 hours. Tag every resource with its owning business unit. This turns cost optimization in aws into an operational habit.
AWS Bedrock Pricing Modes in 2026
Most teams default to on-demand for everything. That is like paying airport daily car rental rates on a vehicle you know you will drive every single day for six months.
| Workload Type | Optimal Pricing Mode | Typical Savings |
|---|---|---|
| Nightly batch jobs | Batch Inference | 50% |
| High-volume steady traffic | Provisioned Throughput | 20–40% |
| Repeated system prompts | Prompt Caching | Up to 90% |
| Mixed-complexity requests | Intelligent Prompt Routing | 25–30% |
Azure AI vs AWS AI: The Cost Reality Check
azure costs are genuinely competitive with aws rates. But if your team holds aws certification credentials and your storage is in amazon storage, the switching cost to azure cloud is 6 to 12 months of migration overhead and parallel-run compute costs.
For most US-based teams, optimizing aws and ai is the correct decision before shopping for a new cloud. The teams that migrate to Azure to escape cost problems almost always bring the same unoptimized architecture patterns with them.
How Braincuber Cuts AWS AI Bills by 40–60% in 90 Days
Typical outcome: $31,000 to $67,000 in annualized savings for companies spending $70K–$150K/month on aws amazon web services AI workloads. Not a projection. Numbers from our last seven client engagements.
5 FAQs on AWS AI Cost Optimization
How much can I realistically cut from my AWS AI bill without reducing output quality?
Most companies running unoptimized aws ai workloads can cut costs by 40–65% using tiered model selection, prompt caching, and batch inference. Average reduction falls around $43,200/month for mid-market.
What is the difference between AWS Bedrock on-demand pricing and provisioned throughput?
On-demand charges per token with zero commitment. Provisioned throughput reserves model capacity at an hourly rate, which becomes cheaper (20–35% savings) at consistent high volumes over 500,000 queries per day.
Does AWS offer free training for AI cost optimization?
AWS provides free courses through AWS Skill Builder covering generative AI architecture basics, but they rarely dive deep into production-scale FinOps implementation patterns required to save thousands.
How does AWS AI cost optimization differ from standard cloud cost optimization?
Standard cloud cost optimization focuses on EC2 right-sizing and S3 lifecycles. AI cost optimization adds dimensions: token economics, inference architecture (real-time vs batch, Multi-Model Endpoints), and MLOps pipeline efficiency.
Is the AWS Solution Architect certification worth pursuing specifically for AI cost governance?
Yes. Teams with certified architects report 22% lower aws rates for equivalent workloads. If your company spends $50K+/month on aws ai ml services, the ROI is usually under 60 days.
Stop letting idle GPU endpoints drain $40,000+ per month.
Book our free 15-Minute AWS AI Cost Audit—we will find your three biggest cost leaks on the first call.