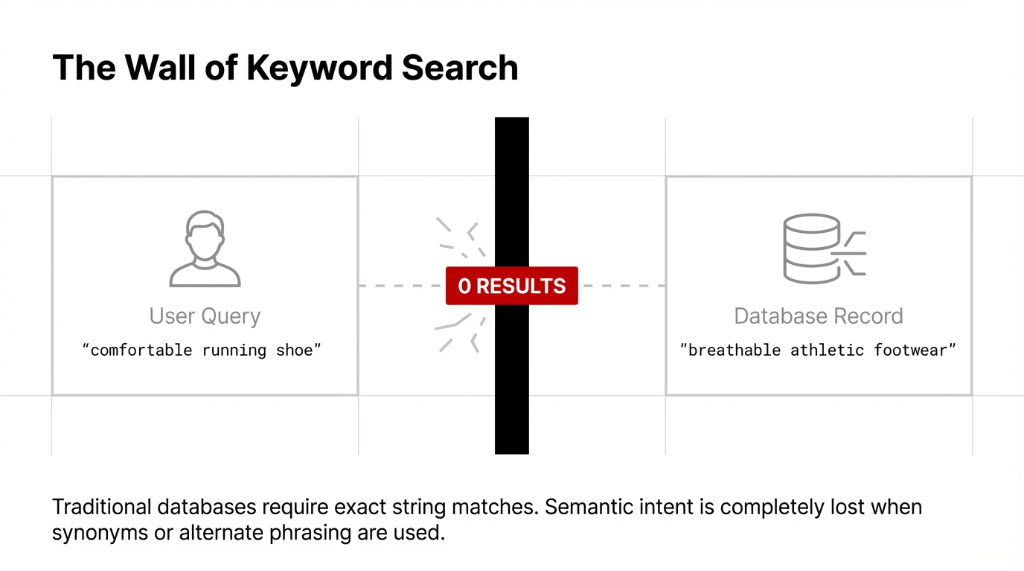
That is the wall traditional keyword search hits. And it is exactly why modern D2C scaling relies heavily on aws cloud based platforms looking for something smarter than exact-string matches.
That something smarter is vector search. We build and deploy this continuously across our US clients. It is the fastest, most scalable way to deploy intent-matching without managing a single server block — if you use Amazon OpenSearch Serverless. Forget the consultant fluff. Let us break down what it actually is, how the engine works, and why this is the missing piece of your data infrastructure strategy.
What Is Amazon OpenSearch Service?
Before we touch serverless, let us ground the basics. Amazon OpenSearch Service is a fully managed, cloud based search and analytics engine. It lets businesses index, search, and analyze large volumes of data in near real-time.
When people say open search AWS or aws open search, they are pointing to this managed offering. It powers everything from full-text product catalogs to high-volume log analytics. But the standard managed service still forces you to choose instance types and manage node counts. We tell Founders strictly to avoid this unless absolutely necessary. We pivot straight to Serverless.
What Is Amazon OpenSearch Serverless?
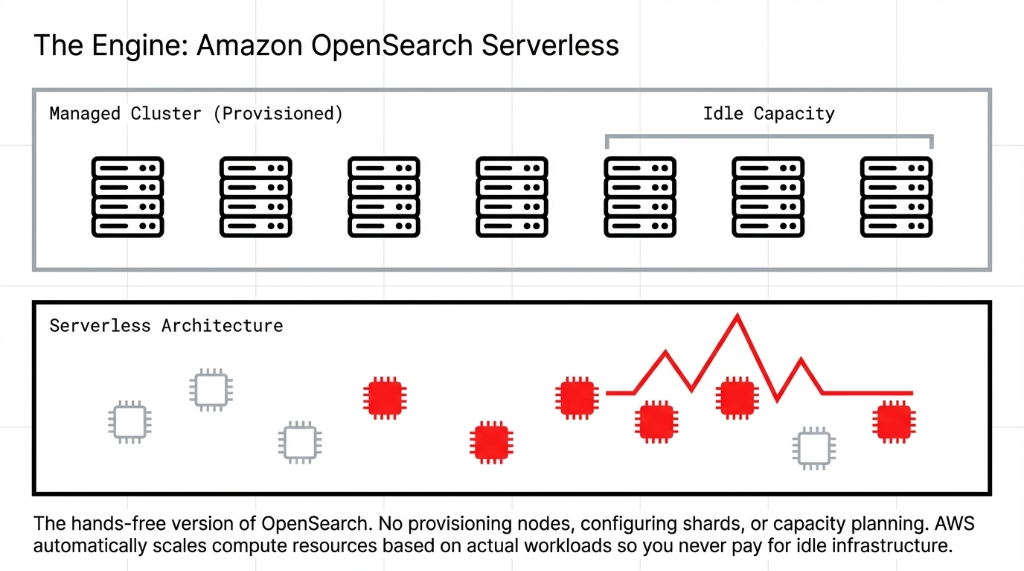
Think of Amazon OpenSearch Serverless as the ultimate "hands-free" version of OpenSearch. You do not provision nodes. You do not configure shards. You do not burn a week on capacity planning. You create a collection, define your access policies, and index your data.
Serverless in AWS Advantage
Capacity: AWS automatically provisions, scales, and maintains the compute and storage resources based entirely on actual workload. Spike in traffic? It scales up. Dead of night? It scales down.
Result
You absolutely never pay for idle infrastructure.
How Amazon OpenSearch Serverless Works Under the Hood
Standard OpenSearch clusters use a single set of instances handling both indexing and searching. This creates a brutal inefficiency: if you need to run more search queries, you are forced to pay for more indexing capacity simultaneously. OpenSearch Serverless breaks that coupling.
It separates indexing compute, search compute, and your amazon s3 storage. A traffic spike in user queries does not force you to scale indexing capacity. This data infrastructure separation enables extreme high availability natively.
Understanding Collection Types
In Amazon OpenSearch Serverless, you build logical groupings called collections. There are exactly three primary workloads we use.

You have Time Series for massive data streaming and log analytics. You have Search for standard structured indexing. And finally, you have Vector Search. Purpose-built for AI-powered similarity matching.
What Is Vector Search? The Complete Explanation
We said this before, but it bears repeating. Vector search works by meaning. It converts content into high-dimensional numerical arrays (vector embeddings). "Running shoes" and "athletic footwear" sit close together in this mathematical space.
Application
Use cases directly translate to lost revenue recovery: Semantic search, product recommendations, anomaly detection, and RAG architectures.
Vector Search + Generative AI: The RAG Connection
A large language model (LLM) knows plenty, but it does not know your actual product catalog. Retrieval-Augmented Generation (RAG) fixes this. Vector search is the retrieval engine.
When a shopper asks a highly specific question, the system converts it into a vector embedding, runs a similarity search in OpenSearch, retrieves your indexed catalog data, and passes it to the LLM. The AI delivers an answer strictly grounded in your business inventory.
Disk-Optimized vs. Memory-Optimized Vectors
Previously, you had memory-optimized vectors demanding massive RAM footprints. This incinerates budget. The 2025 introduction of Disk-Optimized Vectors changed equations completely. It keeps vectors on disk while heavily preserving recall rates, delivering fierce control over storage costs and compute.
OpenSearch Serverless Pricing: What You Actually Pay
Do not let consultant jargon mask billing. You pay $0.24 per OCU-hour for indexing compute. You separately pay $0.24 per OCU-hour for search compute. You pay a trivial $0.024/GB-month for amazon s3 storage. Production baseline requires 4 OCUs. Dev/test requires just 2 OCUs.
Integrations That Extend OpenSearch Serverless
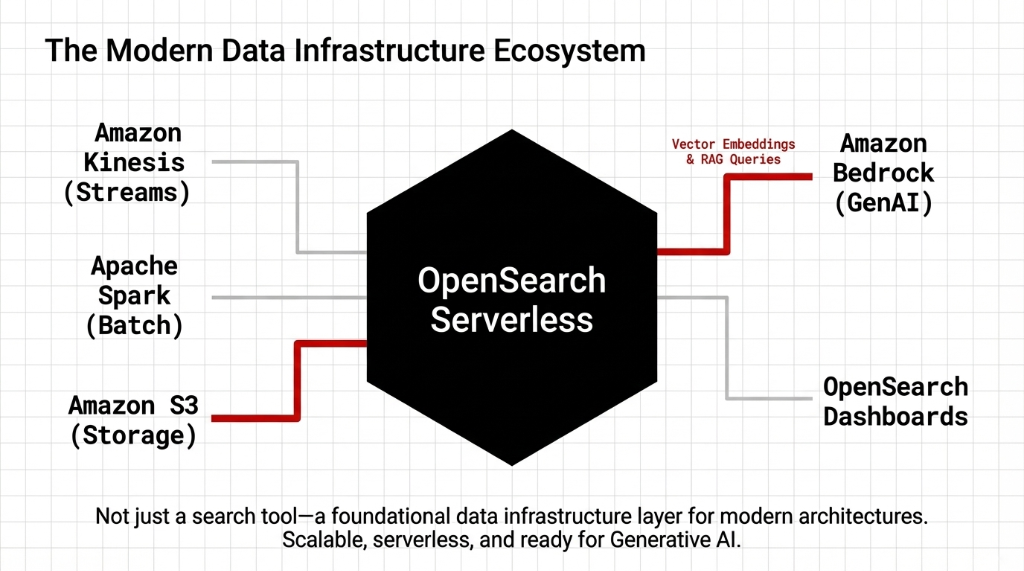
OpenSearch Serverless does not survive in a vacuum. It integrates rapidly into the broader ecosystem pushing real value within amazon aws services.
Ecosystem Highlights
Amazon S3
Native backend for extreme durability entirely decoupled from compute pricing.
Amazon Bedrock
Hooks vector search directly into foundation models for enterprise-grade RAG.
Amazon Kinesis
Feeds live data stream events flawlessly for aggressive log monitoring.
FAQs
What is Amazon OpenSearch Serverless in simple terms?
It is a fully managed, auto-scaling search and analytics service on AWS where you do not manage any servers, clusters, or infrastructure. You just create a collection and start searching or indexing data.
How is vector search different from regular keyword search?
Keyword search matches exact terms. Vector search matches meaning by comparing numerical embeddings. A query for "comfortable shoes" can return "breathable athletic footwear" because the semantic vectors are similar without a shared word.
How does OpenSearch Serverless pricing work?
You pay for OpenSearch Compute Units (OCUs) at $0.24/OCU-hour for indexing and search separately, plus $0.024/GB-month for managed S3 storage. There is no charge for idle clusters, but a minimum baseline of OCUs applies per account.
Can I use OpenSearch Serverless for Generative AI (RAG) applications?
Yes. Vector search collections in OpenSearch Serverless are specifically designed to power RAG pipelines by storing and retrieving embeddings that ground LLM responses in your own business data.
What are the limitations of OpenSearch Serverless compared to a managed cluster?
You cannot configure instance types, shard counts, or low-level cluster settings. There is no multi-tenancy within a single collection, and some advanced tuning options are hidden. For most use cases, these constraints are a fair trade-off for zero operational overhead.
Stop Bleeding Sales to "0 Results" Found
Do not let bad keyword matching drive your customers into the arms of your competitors. We can build your serverless vector search infrastructure rapidly and connect it directly to your custom catalogs.