Here is the ugly truth about single-region aws cloud compute deployments running AI workloads: they have a single throat to choke. When a region experiences even a partial degradation, every inference call and amazon web services lambda function dies simultaneously.
The Two Architecture Patterns (And Which You Need)
There are exactly two patterns worth discussing for multi-region cloud architectures.
Pattern 1: Active-Passive (Hot/Warm/Pilot Light)
One region handles 100% of production traffic. A second region sits ready. This is the right call for 73% of AI workloads we see. The cost gap vs. Active-Active is $9,000–$22,000/month.
Pattern 2: Active-Active
Both regions handle live traffic simultaneously. This demands aggressive execution of global database synchronization and aws route 53 mapping.
The Unified Blueprint
This is exactly how you build absolute multi-regional redundancy without scaling your operational overhead indefinitely.
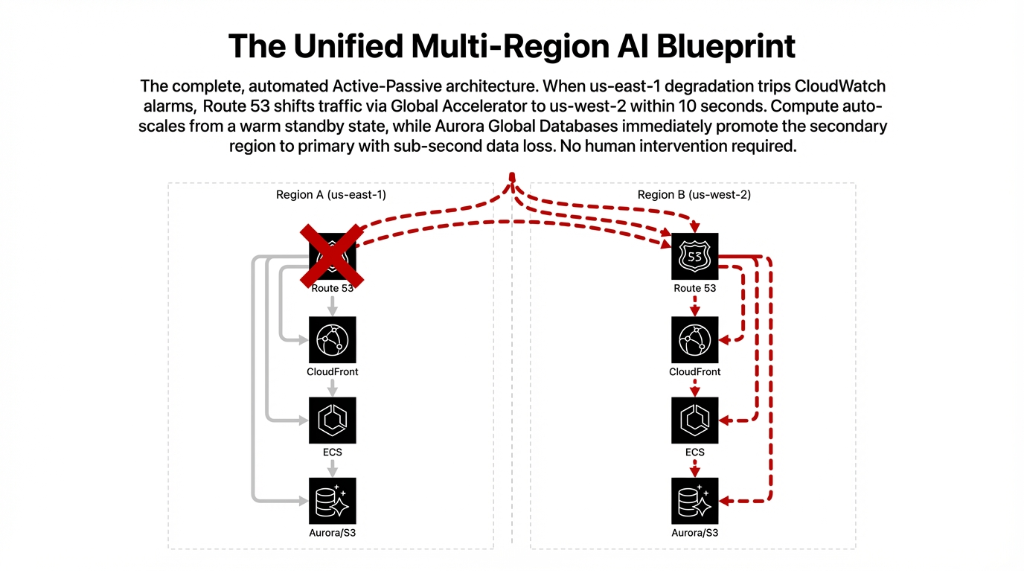
When degradation trips amazon cloudwatch alarms, aws route 53 shifts traffic flawlessly via aws global accelerator within seconds. No human intervention required.
Compute and Container Layers
For containerized AI model serving, replicate strictly across amazon ecr. Connect aws auto scaling across amazon ecs or aws eks node groups with 2 instances minimal per region. Scale on CPU at exactly 60%. Do not wait for 80%. AI workloads burst drastically.
Multi-AZ Redundancy is NOT Disaster Recovery
Do not confuse Multi-AZ with multi-region disaster recovery aws. Multi-AZ protects against localized fires. Multi-Region protects against entire amazon web services outage sweeps.
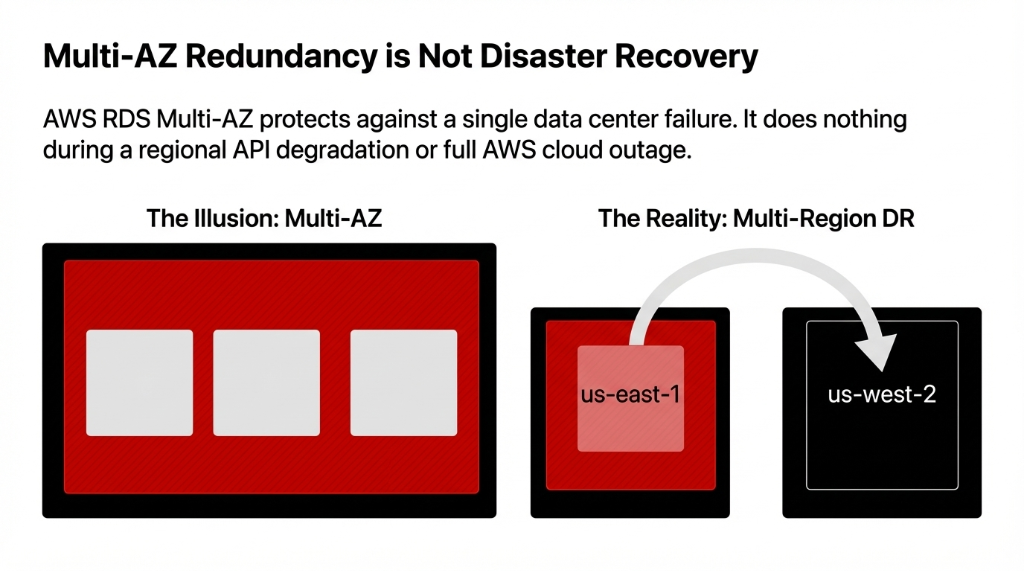
For relational AI metadata, use amazon aurora Global Database. It guarantees an RPO under exactly 1 second across regions. For unstructured data like inference logs and tensors, strictly use storage s3 with CRR cross region replication.
The Economics of Disaster Recovery
Let us put severe truth to business continuity economics based entirely on your recovery time objective.
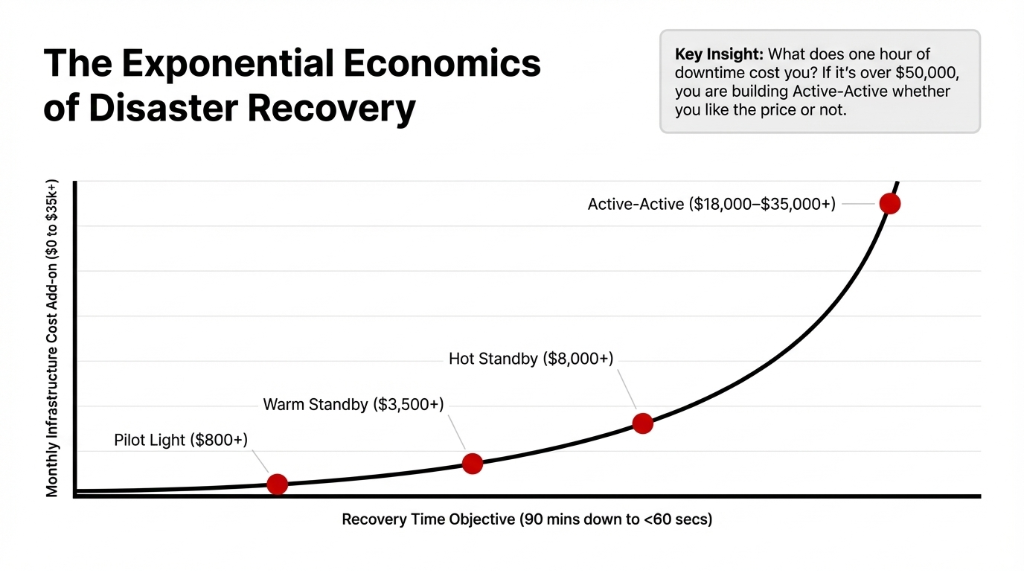
If losing one hour of AI runtime costs over $50,000, you are building an Active-Active deployment pipeline. Do not negotiate on it.
The Braincuber Execution
Our 3-Phase Standard Deployment
Phase 1: Cloud Platform Mapping
We strictly identify stateful architecture gaps before migration bridging services on aws natively.
Phase 2: Code Driven Expansion
Deployment flows strictly through aws cli pushing Terraform configurations so identical redundant clusters generate dynamically.
Phase 3: Automated Failover Runbooks
We drop aws down reaction cycles from hours to seconds connecting directly into AWS Application Recovery Controller.
FAQs
What is the difference between Multi-AZ and Multi-Region on AWS?
Multi-AZ distributes resources across two or three data centers within one AWS region — it protects against a single data center failure. Multi-Region distributes across geographically separate regions and protects against a full regional outage.
How much does a multi-region AWS setup actually cost?
A Warm Standby multi-region setup for a mid-size AI workload runs $3,500–$6,000/month in additional infrastructure. Active-Active starts at $18,000/month.
What AWS services handle data replication across regions?
Amazon Aurora Global Database for relational data, amazon dynamodb Global Tables for key-value and session data, and amazon web s3 Cross-Region Replication for objects and model artifacts.
How do I handle failover without manual intervention?
AWS Route 53 health checks plus aws global accelerator handle traffic rerouting automatically. AWS Application Recovery Controller (ARC) Region Switch enables fully automated regional failover.
Is AWS Lambda a good fit for multi-region AI workloads?
Yes, for stateless components. Lambda functions deploy independently per region and cost virtually nothing at standby. For actual model inference, amazon ecs or aws eks on GPU instances gives you better memory and latency control.
Stop Crossing Your Fingers During Outages
Do not wait for us-east-1 to drop before fixing your pipeline. We blueprint exact Active-Passive flows guaranteeing automated failure migration directly eliminating zero-hour revenue halts.