What This Post Covers
▸ Why vertical scaling gives 2.1x capacity for 3.4x cost — while horizontal microservices give 22x capacity for 1.6x
▸ The 4-layer production architecture handling 10-minute delivery SLAs at 50,000+ orders/day
▸ Edge computing that offloads 61–73% of read traffic and drops response time from 1,400ms to 140ms
▸ KEDA auto-scaling that saved one client $77,143/year without touching a single business feature
▸ AI demand forecasting that cut perishable over-stocking by 23.4% across 14 dark stores
The $62 Billion Market Running on Monoliths
The US quick commerce market sits at $62 billion in 2025, growing at 6.72% CAGR to $85.83 billion by 2030. India is moving even faster — from $1.7 billion in 2025 to a projected $53.5 billion by 2032 at a jaw-dropping 63.2% CAGR. That is not a market you lose because your cloud architecture was designed for 500 orders a day when you are now doing 50,000.
Here is the ugly truth: most grocery and q-commerce platforms are running 2021-era monolithic infrastructure on a 2026 order volume. And it is bleeding them dry.
Why Vertical Scaling Is the Wrong Instinct
Most CTOs facing a spike will immediately call AWS or GCP support and ask to upgrade to a larger instance. That is exactly what you should not do.
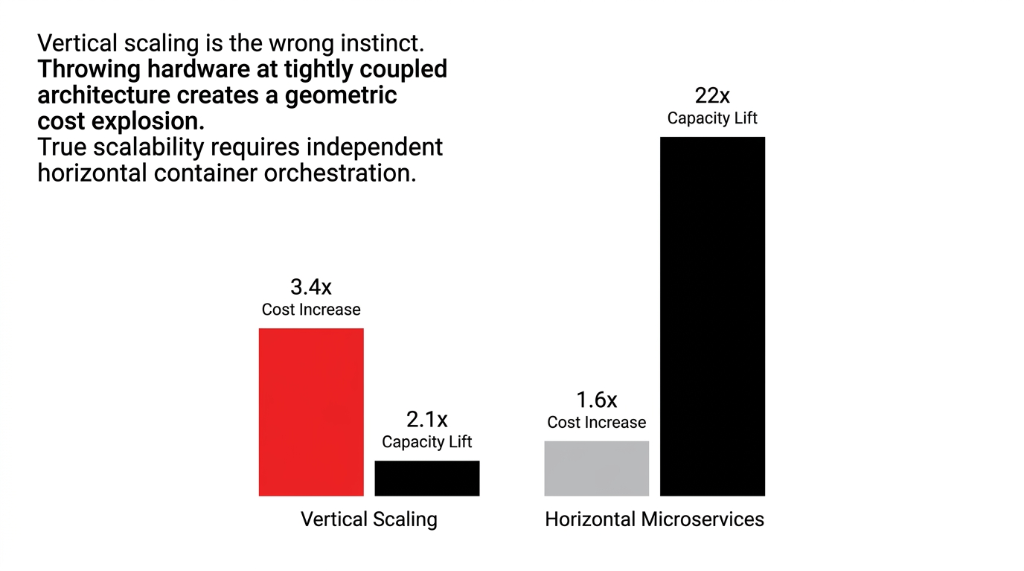
Vertical scaling (bigger server) gives you maybe a 2.1x capacity lift for a 3.4x cost increase. Horizontal scaling via microservices and container orchestration gives you 22x capacity for 1.6x cost — but only if your services are properly decoupled.
The global commerce cloud market hit $26.8 billion in 2025 and is projected to reach $165.9 billion by 2035, growing at 20% CAGR. That capital is going into one place: event-driven, microservices architectures that scale individual components independently. Docker + Kubernetes (K8s) makes this possible by letting you auto-scale specific microservices — scaling the Order Service at peak hours on Saturday night without paying for extra capacity on the Vendor Portal every day.
The 4-Layer Cloud Architecture That Actually Works
This is the architecture we deploy at Braincuber for quick commerce clients handling 10-minute delivery SLAs. Not a concept — this is what is running in production.
Layer 1 — The Edge Layer
Your customer-facing API must never go down, even when your backend is under stress. This means putting Cloudflare or AWS CloudFront as the first line — not just for CDN asset delivery, but for edge computing.
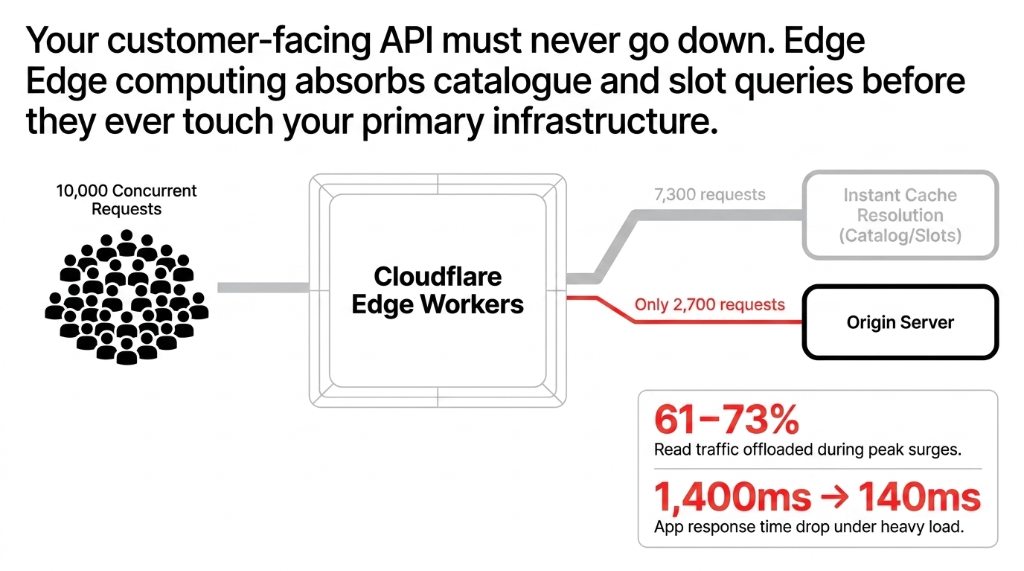
Edge workers handle traffic spikes during flash sales by absorbing read requests (product catalog, store availability, slot availability) directly at the CDN level, without touching your origin server. This alone offloads 61–73% of your read traffic during peak hours. Your app response time goes from 1,400ms under load to 140ms. That is the difference between a customer placing an order and bouncing to Zepto.
Layer 2 — The API Gateway + Circuit Breaker
Everything in quick commerce moves through events. When a customer places an order, it triggers: inventory reservation (under 800ms), payment authorization (under 1.2s), rider assignment (under 3s from order confirm), and dark store pick queue update (under 5s).
An API Gateway (AWS API Gateway, Kong, or NGINX) handles routing, rate limiting, and authentication. Behind it, a service mesh (Istio or Linkerd) handles service-to-service communication, circuit breaking, and retry logic.
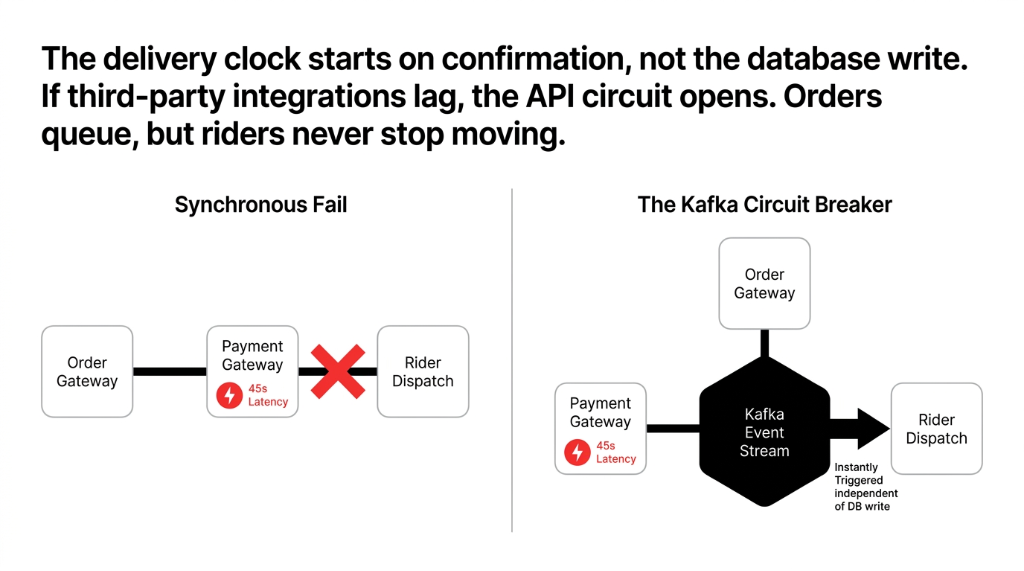
The circuit breaker pattern saves you when Razorpay or Stripe has a 45-second latency spike. Instead of all 4,200 concurrent order requests hanging and timing out, the circuit opens — orders queue in Kafka, payments retry on restore, and your riders never stop moving.
Layer 3 — The Event-Driven Core
Apache Kafka or AWS Kinesis is the spine of a production-grade q-commerce platform. Every action becomes an event. Every event is consumed by the service that needs it — asynchronously.
In quick commerce, the delivery clock starts the moment the customer hits confirm — not the moment your database finishes writing. With synchronous architecture, a slow DB write blocks the rider dispatch. With an event stream, the "order confirmed" event fires instantly, the rider dispatch service picks it up in 120ms, and the DB write happens in parallel. This is how Zepto and Blinkit handle millions of orders at scale.
Layer 4 — The Data Layer (The One Nobody Architects Properly)
Here is where most q-commerce platforms bleed quietly for months. You need four different data stores, each doing a specific job:
| Store Type | Tool | Purpose |
|---|---|---|
| In-Memory Cache | Redis Cluster | Live inventory counts, session data, cart state. 1.2 million reads/second. |
| Transactional DB | AWS Aurora PostgreSQL | ACID-compliant order records, payment history, user accounts. |
| Analytical Store | Snowflake or BigQuery | Demand forecasting, dark store restocking triggers. |
| Search Engine | Elasticsearch | Product catalog, autocomplete at millisecond speed. |
The Single-DB Mistake That Craters Your Checkout
Teams using a single PostgreSQL instance for all four workloads will hit 94% CPU when 12,000 concurrent users attack search and checkout simultaneously. Response time balloons. Carts do not load. Orders fail silently.
Dark Store Ops Are a Cloud Problem, Not a Warehouse Problem
Quick commerce platforms handling 70–75% of all e-grocery orders today are not winning on warehouse efficiency alone. They are winning because their inventory state is real-time accurate to within 3 seconds across every dark store.
If that sync has an 18-second lag (typical for polling-based systems), and your customer places an order for the last bottle of cold-pressed juice at second 4, you have just made a promise you cannot keep. The fix: WebSocket-based real-time inventory push from the picker device to the central inventory service, writing to Redis first, then persisting asynchronously to Aurora. Latency drops from 18 seconds to under 2 seconds. Mis-picks at dark stores drop by 31–38%.
MLOps and AI: Where Cloud Architecture Gets Its ROI Back
We run demand forecasting models on AWS SageMaker for q-commerce clients that predict SKU-level demand 4–6 hours ahead, by dark store, by day part, by weather. One client reduced over-stocking of perishables by 23.4% and cut food wastage costs by $22,262/month across 14 dark stores.
Rider routing optimization runs on GCP Vertex AI or AWS Bedrock — processing real-time GPS, traffic, and order clustering data to reduce average delivery distance by 1.1–1.7 km per order. At $0.048–$0.071 per km in fuel cost per rider, that is $0.053–$0.121 saved per delivery. At 40,000 daily orders, that math gets very interesting very fast.
The Infrastructure Cost Reality Nobody Tells You
Frankly, most q-commerce CTOs are overpaying for cloud by 31–45%. They are running on-demand EC2 instances for workloads that are 100% predictable — like the nightly inventory reconciliation job that runs every day at 2 AM without fail. That job should be on a Spot Instance or Reserved Instance. Cost savings: 67–72% versus on-demand pricing.
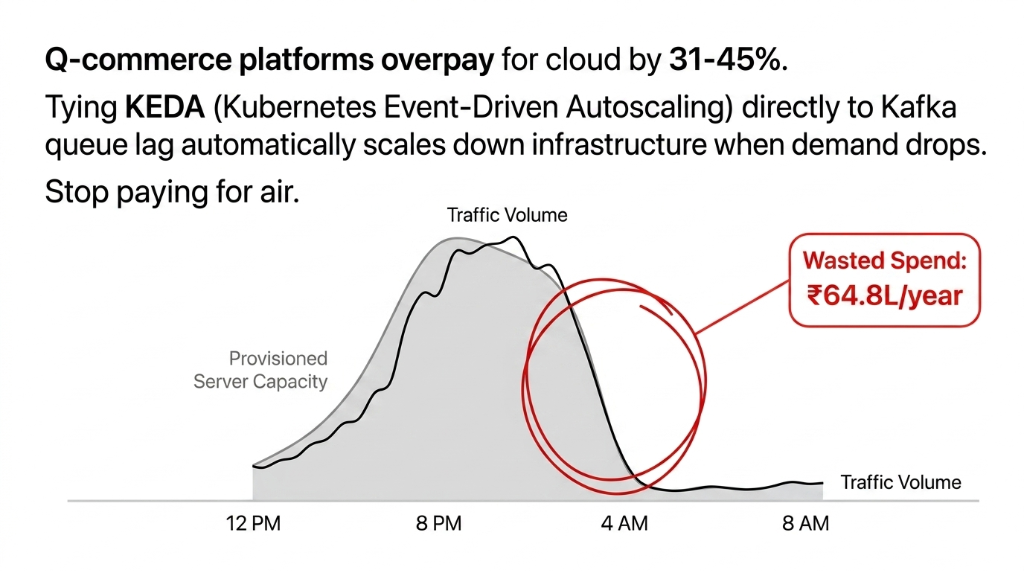
The second leak: no auto-scaling policies with scale-down triggers. Teams configure scale-up (because they are scared of downtime) but forget that the extra pods provisioned for Saturday's peak are still running at full cost on Tuesday morning at 4 AM. Implement KEDA (Kubernetes Event-Driven Autoscaling) tied to your Kafka consumer lag metric. One client went from a fixed $16,905/month AWS bill to a variable $10,595/month average — saving $77,143 annually without touching a single business feature.
Quick Commerce Cloud Architecture Stack
Edge + CDN
Cloudflare Workers + AWS CloudFront. Absorbs 61–73% of read traffic during spikes.
Container Orchestration
Kubernetes (EKS/GKE) + KEDA. Per-service scaling, 67% infra cost reduction.
Event Streaming + Caching
Apache Kafka / AWS Kinesis for async order flow. Redis Cluster for 1.2M reads/sec inventory sync.
ML + Service Mesh
AWS SageMaker / Vertex AI for demand prediction. Istio / Linkerd for circuit breaking and observability.
Build vs. Buy — The Controversial Opinion
Stop trying to build your own real-time order tracking engine from scratch. Three companies in India have spent $8–22 million building what Google Maps Platform's Logistics API + a thin integration layer can do for $1,800/month.
Buy the commodity infrastructure: maps, routing, payment gateway, SMS/push notification infra. Build the differentiation: your demand forecasting model (your data is your moat), your dark store pick sequence optimization, your hyperlocal pricing engine. This split typically lets a 12-person engineering team punch at the level of a 40-person team.
Frequently Asked Questions
What cloud architecture does quick commerce use for 10-minute delivery?
Event-driven microservices on Kubernetes, with Redis for real-time inventory caching (sub-2s sync), Apache Kafka for async order processing, and edge computing via Cloudflare to absorb traffic spikes. Each service — orders, dispatch, inventory, payments — scales independently.
How does cloud auto-scaling work for grocery delivery platforms?
KEDA (Kubernetes Event-Driven Autoscaling) ties scaling decisions to Kafka consumer lag or order queue depth — not just CPU. During peak hours, Order Processing pods scale up in 90–120 seconds. When volume drops, they scale back down automatically, cutting average monthly cloud bills by 31–45%.
What is the role of dark stores in cloud architecture for quick commerce?
Dark stores generate continuous real-time inventory events that must sync to the central platform in under 3 seconds. The architecture uses WebSocket-based push from picker devices to a Redis cache layer, with asynchronous writes to Aurora. This eliminates 18-second polling lag and reduces mis-pick rates by 31–38%.
How does AI demand forecasting connect to cloud infrastructure in q-commerce?
Demand forecasting models run on AWS SageMaker or GCP Vertex AI, pulling order history from Redshift or BigQuery and running SKU-level inference every 4–6 hours per dark store. Recommendations push directly into the WMS via API. This cuts perishable over-stocking by 20–24%.
How much does a production-grade q-commerce cloud architecture cost?
A well-optimized setup for 30,000–50,000 daily orders typically runs $9,524–$17,857/month on AWS or GCP — compared to $21,429–$29,762/month for unoptimized, always-on infrastructure. Primary savings: Spot/Reserved Instances, KEDA scale-down, and edge CDN offloading.
Do Not Let Bad Cloud Architecture Cap Your Growth Ceiling
Book our free 15-Minute Cloud Architecture Audit — we will find your biggest infrastructure leak in the first call. Your next Saturday night surge does not have to end with 2,300 orders in limbo and a 2 AM damage-control call.
Stop paying for air. Start paying for architecture.