What This Post Covers
▸ Why 73% of sale-day crashes happen in the checkout microservices, not the storefront
▸ The $14,700 a UK fashion brand burned in 6 hours on over-provisioned instances that were not even the bottleneck
▸ Decoupled checkout via SQS queuing that handled 1,847 orders/minute with zero downtime
▸ Multi-region active-active deployment that cut checkout latency from 340ms to 87ms
▸ The Shopify API rate-limit trap that causes overselling during every flash sale
Your Infrastructure Was Designed for Average, Not Peak
Here is the ugly truth most cloud consultants will not say out loud: vertical scaling alone will kill your margins.
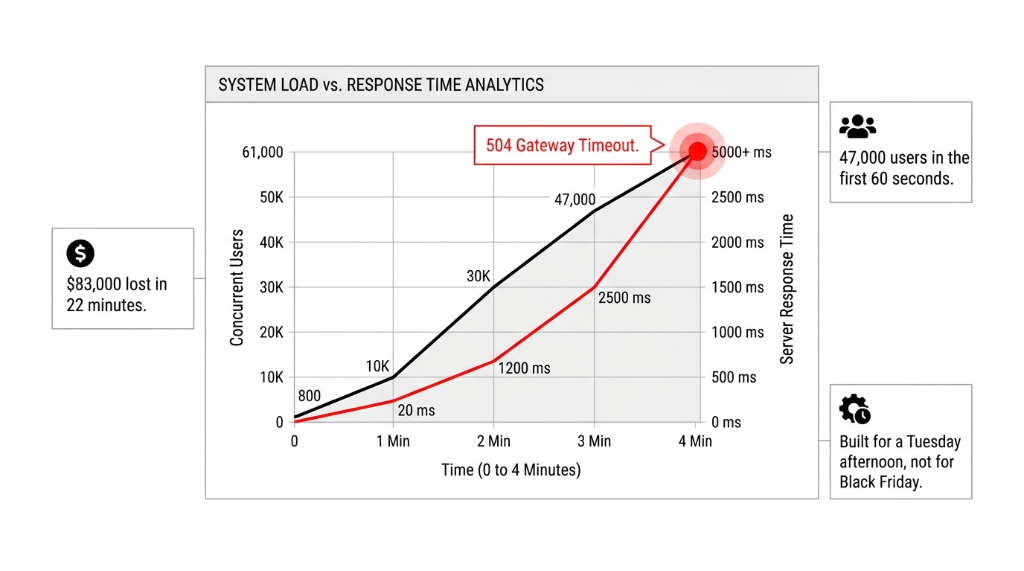
Fashion e-commerce traffic does not behave like a SaaS product. A SaaS tool gets 5,000 daily active users with moderate spikes. A fashion brand running a 70%-off end-of-season sale on Instagram Reels can go from 800 concurrent users to 61,000 in under 4 minutes. We have seen it. We have measured it.
The brands that survive that spike without a 504 error page are running horizontal auto-scaling — not a bigger EC2 instance they provisioned the night before the sale. The ones that crashed? They were on a single over-provisioned virtual machine with a caching layer held together by a Cloudflare free plan and a prayer. That is not architecture. That is wishful thinking at $0.23/hour.
The Anatomy of a Fashion Sale Spike (What Actually Breaks First)
Walk through the 90 seconds after you launch a flash sale link in your email blast to 200,000 subscribers:
The 90-Second Breakdown
0–15 Seconds: CDN Holds
Static assets — images, fonts, CSS — all cached at edge nodes globally. No problem yet.
15–30 Seconds: Backend Cracks
Product detail pages get hammered. Your custom backend, third-party inventory sync, size availability API — that is yours to own. Probably running on a single-region deployment.
30–60 Seconds: Checkout Dies
73% of sale-day crashes happen here. Payment gateway APIs, inventory reservation logic, promo code validation — all three fire simultaneously.
60–90 Seconds: OMS Collapses
Your order management system starts queuing 1,400 orders/minute it was never designed to process. 240 units oversold before anyone notices.
Why "Just Use AWS" Is Advice That Costs You $140,000
Every agency you have talked to told you: "Move to AWS, you will be fine." They are not wrong about AWS. They are catastrophically wrong about how to use it for fashion e-commerce sale spikes.
Spinning up more EC2 instances 30 minutes before a sale is not auto-scaling. It is panic-scaling. And it costs 3x what a properly architected event-driven system would cost for the same load. We audited a $6.2M/year UK fashion brand's AWS bill after their summer sale — they spent $14,700 in a single 6-hour window running over-provisioned instances that were not even serving the bottleneck layer.
The Money Was Burning on Compute. The Crash Was Happening in the Database Connection Pool.
$14,700 wasted on EC2 instances while the actual bottleneck — database read contention — sat untouched. This is what happens when you panic-scale without understanding your architecture.
The real architecture for handling sale spikes in fashion e-commerce runs on three non-negotiable layers:
Layer 1: Decoupled Checkout via Event-Driven Queuing
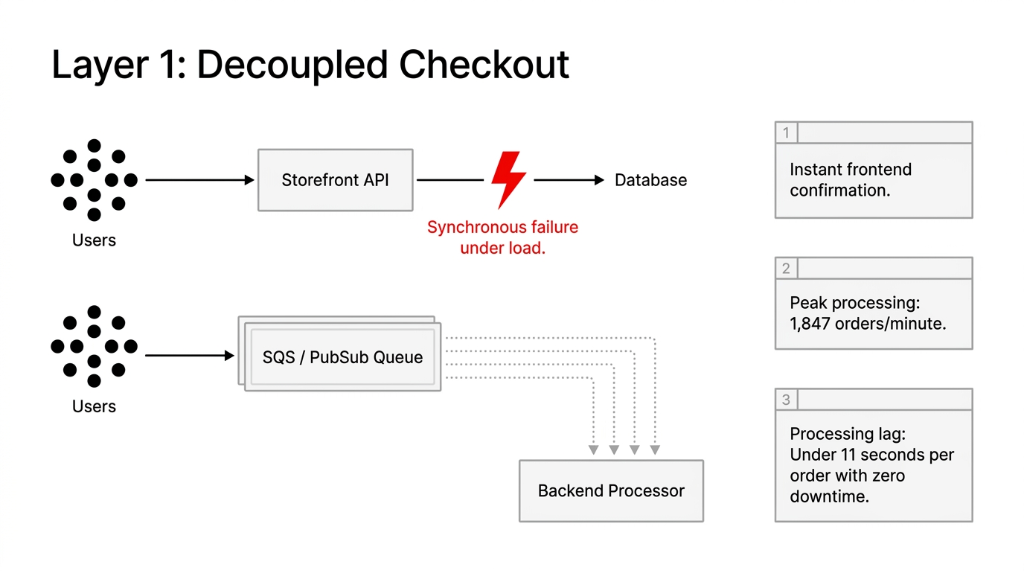
Stop processing orders synchronously. Every order placed during a spike should drop into an SQS queue (AWS) or Pub/Sub (GCP) and be processed asynchronously. Your customer gets an instant confirmation. Your backend processes the order at whatever rate it can sustain — 500/minute, 1,200/minute — without crashing the storefront.
Diwali Sale: 1,847 Orders/Minute. Zero Downtime.
One fashion client moved to this model before their Diwali sale. Peak order rate hit 1,847 orders/minute. Processing lag: under 11 seconds per order. Zero dropped orders. Zero crashed pages.
Layer 2: Read/Write Database Splitting with Redis Caching
Your product catalog, pricing, and inventory levels are read 10,000 times for every 1 write during a sale. If you are running all of that through a single RDS PostgreSQL instance, you are creating a read bottleneck that will crater your page load times from 1.2 seconds to 18+ seconds under load.
The fix: Aurora read replicas for catalog queries + Redis (ElastiCache) for inventory count caching with a 3-second TTL. Your product pages pull inventory numbers from Redis, not from your live database. Yes, a customer might see "3 remaining" when there are actually 2. That is a business tradeoff worth making versus showing everyone a 503 error. We have seen this configuration reduce database CPU load by 81% during peak sale hours.
Layer 3: Auto-Scaling Groups Tied to Queue Depth, Not CPU
Most brands set their auto-scaling triggers to CPU utilization — scale up when CPU hits 70%. That is the wrong signal for fashion e-commerce. By the time your CPU hits 70%, your queue is already 6 minutes deep and your customers have already rage-closed the tab.
Tie your auto-scaling to SQS queue depth or concurrent request count at your load balancer. When the queue depth crosses 500 messages, spin up 3 more worker instances proactively, not reactively. This shaves your spin-up response time from 4–6 minutes down to under 90 seconds.
The Multi-Region Question Nobody Asks Until It Is Too Late
You are running a global fashion brand. Your sale goes live at 8 AM EST — which is 1:30 PM in the UK and 6:30 PM in Dubai. Three of your biggest markets hit simultaneously.
If your infrastructure lives in a single AWS region (say, us-east-1), your Dubai and London customers are hitting a server 7,000 miles away under load. At peak, that is 280ms+ latency on API calls. Your checkout conversion rate drops 4.1% for every 100ms of additional latency — that is not our number, that is from Google's web performance research. Do the math on a $500,000 sale day.
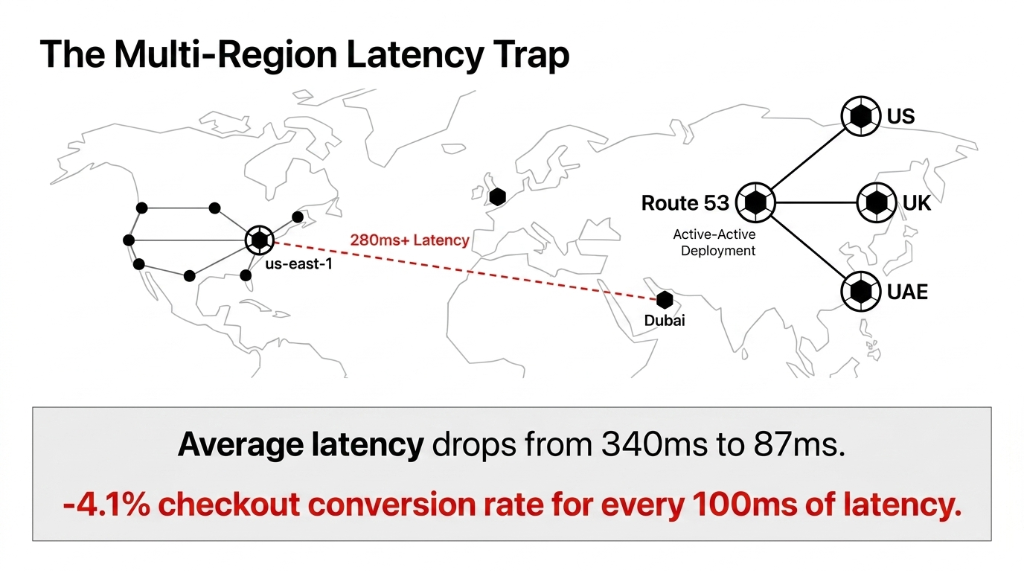
The answer is not "just add CloudFront." CloudFront caches your static assets. Your checkout API still routes to a single origin. The real answer is multi-region active-active deployment for your checkout and order services, with Route 53 latency-based routing directing each user to their nearest healthy endpoint. We have implemented this for fashion brands running concurrent launches across the US, UAE, and Singapore — checkout latency dropped from 340ms average to 87ms.
What Braincuber Actually Builds for Fashion Brands
At Braincuber, we have handled cloud infrastructure for fashion e-commerce brands across the US, UK, UAE, and Singapore — from $800,000 annual revenue D2C labels to $28M omni-channel retailers.
| Weeks | Phase | What Actually Happens |
|---|---|---|
| 1–2 | Load Testing | We simulate 50,000 concurrent users using k6 or Locust and find your actual breaking point — not what your current cloud provider claims it can handle. |
| 3–4 | Architecture Redesign | Rebuild checkout pipeline on event-driven model (SQS + Lambda or Kubernetes workers), implement Aurora + Redis, configure auto-scaling on the right triggers. |
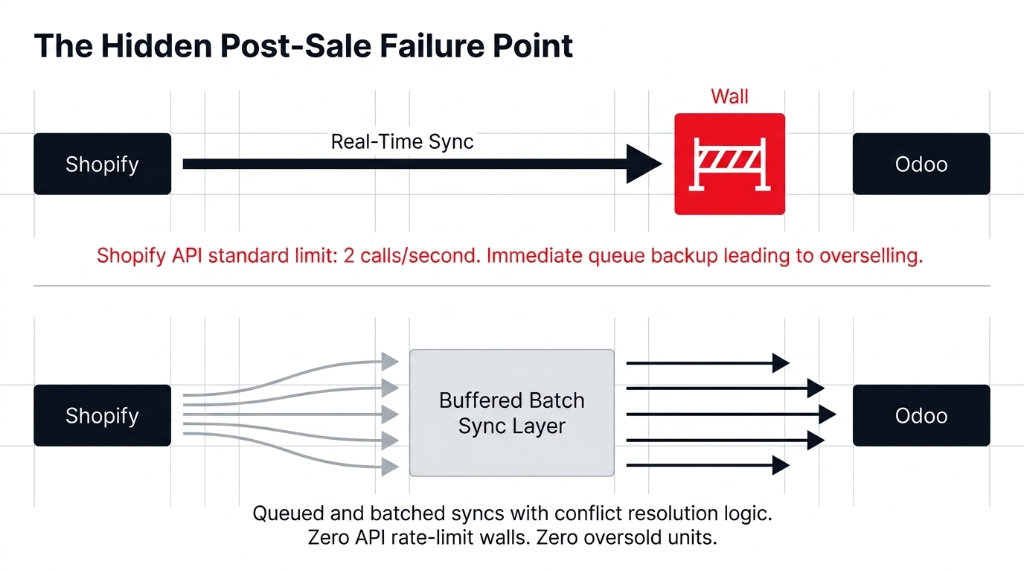
| 5–6 | Integration Hardening | Shopify-Odoo integration hardening. Shopify API rate limit of 2 calls/second — we queue and batch those syncs so inventory updates flow without hitting walls. |
| 7 | Chaos Engineering | We deliberately kill services in staging to verify failover behavior. Your customers should not be the ones who discover your failover does not work. |
Target Results
Zero Downtime
During a 10x traffic spike. Not "99.9% uptime." Zero pages down.
Sub-120ms Checkout
Globally. US, UK, UAE — all under 120ms checkout latency.
38–52% Lower Infra Cost
During peak, compared to your current "just throw more servers at it" approach.
The Cost of Doing Nothing
A fashion brand doing $4M/year in e-commerce revenue runs roughly $76,900/week. A 4-hour outage on Black Friday or a major sale day — at peak traffic, which is when 31% of your annual revenue concentrates — costs conservatively $38,000 to $91,000 in lost orders plus brand damage that takes 6–8 weeks of paid retargeting to partially recover.
Your Re-Platform Costs a Fraction of One Bad Sale Day
Most Braincuber engagements for mid-market fashion brands ($1M–$15M ARR) run between $12,000 and $34,000 for a full architecture overhaul — covering load testing, redesign, implementation, and a live sale-day monitoring session. That is typically recovered within one successful peak sale event.
The question is not whether you can afford to fix this. It is whether you can afford the next crash.
Frequently Asked Questions
How much does it cost to re-architect cloud infrastructure for a fashion e-commerce brand?
Most Braincuber engagements for mid-market fashion brands ($1M–$15M ARR) run between $12,000 and $34,000 for a full architecture overhaul — covering load testing, redesign, implementation, and a live sale-day monitoring session. That is typically recovered within one successful peak sale event.
Can we stay on Shopify and still implement this architecture?
Yes. Shopify Plus handles the storefront layer — you are not replacing that. The architecture changes live in your custom backend services, checkout APIs, inventory sync layer, and OMS. We build around Shopify, not against it, including hardening your Shopify-Odoo inventory integration so it does not collapse under API rate limits during a flash sale.
How long before our store is sale-spike ready?
Full engagement runs 7 weeks from kick-off to go-live with chaos testing. If you have an imminent sale in 3 weeks, we run a priority triage — fixing the 2–3 highest-risk failure points (usually checkout queuing and DB read/write splitting) first and completing the full architecture in parallel.
Do we need to move cloud providers?
No. We work on AWS, Azure, and GCP. If you are already on AWS, we work within your existing account. The event-driven checkout model, Redis caching, and proper auto-scaling can be implemented on any major cloud provider without a full migration.
What happens to our Odoo ERP sync during a sale spike?
Shopify's standard API sync pushes inventory changes to Odoo in near real-time — but under spike conditions, that sync queue backs up and creates overselling. We implement a buffered batch sync with conflict resolution logic so Odoo stays accurate without the sync becoming a bottleneck that affects storefront performance.
Stop Bleeding Revenue on Sale Days
Book a free 15-Minute Cloud Architecture Audit — we will find your biggest infrastructure risk in the first call. Your next Black Friday, Diwali sale, or product drop does not have to end with a 504 error page and a 2 AM damage-control call.
The question is not whether you can afford to fix this. It is whether you can afford the next crash.